#import module dan package yang diperlukanimport pandas as pd
import matplotlib.pyplot as pltimport numpy as np
%matplotlib inline
Pengenalan Pandas
Pandas adalah salah satu package andalan python untuk melakukan analysis. Pada praktikum kali ini, kami akan memperkenalkan beberapa fungsi penting yang sering digunakan pada pandas
Pada module kali ini, akan digunakan data csv Fuel Consumption of CO2 (FuelConsumptionCo2.csv) yang bisa didownload dari:
#mencetak nama nama index dari dataframeprint(df.index)
RangeIndex(start=0, stop=1067, step=1)
#Selanjutnya, kita dapat melakukan eksploratory data analysis (EDA) menggunakan pandasdf.describe()
MODELYEAR
ENGINESIZE
CYLINDERS
FUELCONSUMPTION_CITY
FUELCONSUMPTION_HWY
FUELCONSUMPTION_COMB
FUELCONSUMPTION_COMB_MPG
CO2EMISSIONS
count
1067.0
1067.000000
1067.000000
1067.000000
1067.000000
1067.000000
1067.000000
1067.000000
mean
2014.0
3.346298
5.794752
13.296532
9.474602
11.580881
26.441425
256.228679
std
0.0
1.415895
1.797447
4.101253
2.794510
3.485595
7.468702
63.372304
min
2014.0
1.000000
3.000000
4.600000
4.900000
4.700000
11.000000
108.000000
25%
2014.0
2.000000
4.000000
10.250000
7.500000
9.000000
21.000000
207.000000
50%
2014.0
3.400000
6.000000
12.600000
8.800000
10.900000
26.000000
251.000000
75%
2014.0
4.300000
8.000000
15.550000
10.850000
13.350000
31.000000
294.000000
max
2014.0
8.400000
12.000000
30.200000
20.500000
25.800000
60.000000
488.000000
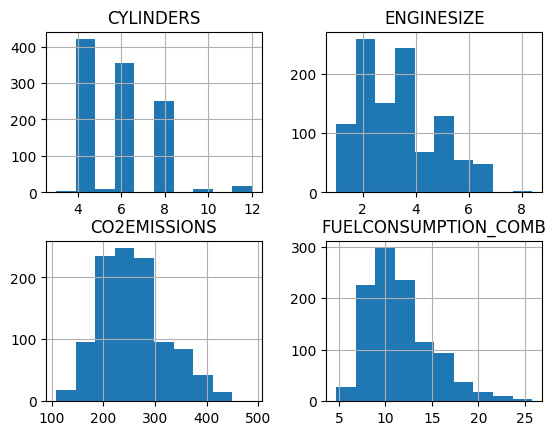
describe akan menampilkan statistik deskriptif dari dataframe tersebut - count (jumlah baris), - mean (rata rata), - std (standar deviation/simpangan baku), - min (nilai minimum), - 25% (quartil pertama), - 50% (quartil kedua), - 75% (quartil ketiga) - max (nilai maksimum)
#kita juga dapat mengambil beberapa kolom tertentu dari dataframe, misal kita akan mengambil kolom enginesize, cylinder, fuelconsumption_city, fuelcomsumtion_hwy, fuelcomsumption_comb, dan co2emissionsnew_df = df[['ENGINESIZE','CYLINDERS','FUELCONSUMPTION_CITY','FUELCONSUMPTION_HWY','FUELCONSUMPTION_COMB','CO2EMISSIONS']]new_df.head(9)
ENGINESIZE
CYLINDERS
FUELCONSUMPTION_CITY
FUELCONSUMPTION_HWY
FUELCONSUMPTION_COMB
CO2EMISSIONS
0
2.0
4
9.9
6.7
8.5
196
1
2.4
4
11.2
7.7
9.6
221
2
1.5
4
6.0
5.8
5.9
136
3
3.5
6
12.7
9.1
11.1
255
4
3.5
6
12.1
8.7
10.6
244
5
3.5
6
11.9
7.7
10.0
230
6
3.5
6
11.8
8.1
10.1
232
7
3.7
6
12.8
9.0
11.1
255
8
3.7
6
13.4
9.5
11.6
267
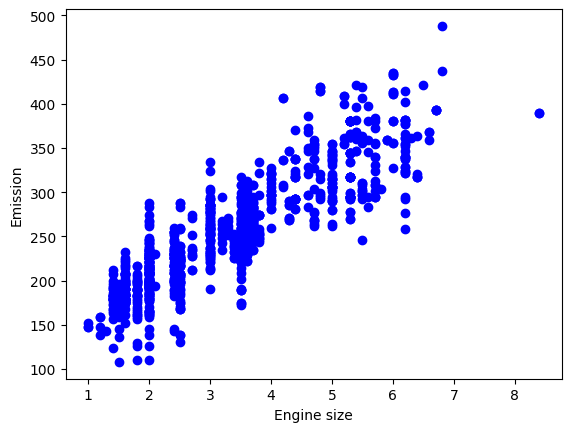
#kita juga dapat mengambil row dengan kondisi tertentu, untuk value numericbig_engine = df[df["ENGINESIZE"]>4]big_engine.head()
MODELYEAR
MAKE
MODEL
VEHICLECLASS
ENGINESIZE
CYLINDERS
TRANSMISSION
FUELTYPE
FUELCONSUMPTION_CITY
FUELCONSUMPTION_HWY
FUELCONSUMPTION_COMB
FUELCONSUMPTION_COMB_MPG
CO2EMISSIONS
12
2014
ASTON MARTIN
DB9
MINICOMPACT
5.9
12
A6
Z
18.0
12.6
15.6
18
359
13
2014
ASTON MARTIN
RAPIDE
SUBCOMPACT
5.9
12
A6
Z
18.0
12.6
15.6
18
359
14
2014
ASTON MARTIN
V8 VANTAGE
TWO-SEATER
4.7
8
AM7
Z
17.4
11.3
14.7
19
338
15
2014
ASTON MARTIN
V8 VANTAGE
TWO-SEATER
4.7
8
M6
Z
18.1
12.2
15.4
18
354
16
2014
ASTON MARTIN
V8 VANTAGE S
TWO-SEATER
4.7
8
AM7
Z
17.4
11.3
14.7
19
338
#kita juga dapat mengambil row dengan kondisi tertentu, untuk value lainnyaaston_martin_cars = df[df["MAKE"].isin(["ASTON MARTIN"])]aston_martin_cars
MODELYEAR
MAKE
MODEL
VEHICLECLASS
ENGINESIZE
CYLINDERS
TRANSMISSION
FUELTYPE
FUELCONSUMPTION_CITY
FUELCONSUMPTION_HWY
FUELCONSUMPTION_COMB
FUELCONSUMPTION_COMB_MPG
CO2EMISSIONS
12
2014
ASTON MARTIN
DB9
MINICOMPACT
5.9
12
A6
Z
18.0
12.6
15.6
18
359
13
2014
ASTON MARTIN
RAPIDE
SUBCOMPACT
5.9
12
A6
Z
18.0
12.6
15.6
18
359
14
2014
ASTON MARTIN
V8 VANTAGE
TWO-SEATER
4.7
8
AM7
Z
17.4
11.3
14.7
19
338
15
2014
ASTON MARTIN
V8 VANTAGE
TWO-SEATER
4.7
8
M6
Z
18.1
12.2
15.4
18
354
16
2014
ASTON MARTIN
V8 VANTAGE S
TWO-SEATER
4.7
8
AM7
Z
17.4
11.3
14.7
19
338
17
2014
ASTON MARTIN
V8 VANTAGE S
TWO-SEATER
4.7
8
M6
Z
18.1
12.2
15.4
18
354
18
2014
ASTON MARTIN
VANQUISH
MINICOMPACT
5.9
12
A6
Z
18.0
12.6
15.6
18
359
#sorting rows dari yg kecil ke yang besarsorted_df = new_df.sort_values("ENGINESIZE")sorted_df.head()
ENGINESIZE
CYLINDERS
FUELCONSUMPTION_CITY
FUELCONSUMPTION_HWY
FUELCONSUMPTION_COMB
CO2EMISSIONS
938
1.0
3
6.9
5.7
6.4
147
939
1.0
3
6.9
5.7
6.4
147
394
1.0
4
7.5
5.5
6.6
152
824
1.2
3
6.4
5.4
6.0
138
260
1.2
4
7.6
6.0
6.9
159
#sorting rows dari yg besar ke yg kecilsorted_df_des = new_df.sort_values("ENGINESIZE", ascending =False)sorted_df_des.head()
ENGINESIZE
CYLINDERS
FUELCONSUMPTION_CITY
FUELCONSUMPTION_HWY
FUELCONSUMPTION_COMB
CO2EMISSIONS
940
8.4
10
20.0
13.0
16.9
389
941
8.4
10
20.0
13.0
16.9
389
75
6.8
8
22.3
14.9
19.0
437
349
6.8
10
23.9
17.8
21.2
488
924
6.7
12
20.7
12.8
17.1
393
#menambah kolom baru, pada contoh ini menambahkan kolom FUELCON_AVERAGEdf["FUELCON_AVERAGE"]=(df["FUELCONSUMPTION_CITY"]+df["FUELCONSUMPTION_HWY"]+df["FUELCONSUMPTION_COMB"])/3df.head()