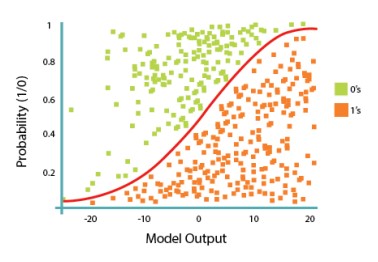
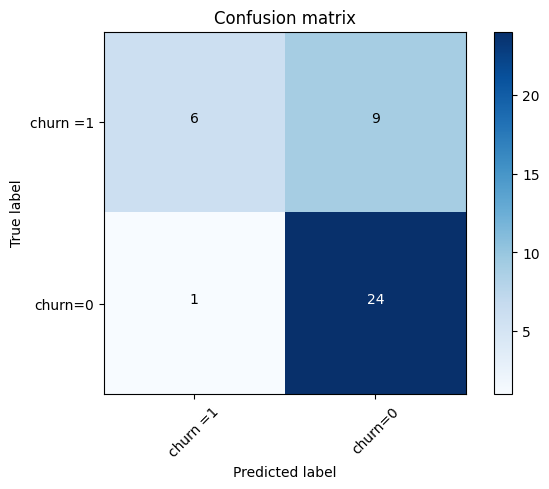
array([[0.54132919, 0.45867081],
[0.60593357, 0.39406643],
[0.56277713, 0.43722287],
[0.63432489, 0.36567511],
[0.56431839, 0.43568161],
[0.55386646, 0.44613354],
[0.52237207, 0.47762793],
[0.60514349, 0.39485651],
[0.41069572, 0.58930428],
[0.6333873 , 0.3666127 ],
[0.58068791, 0.41931209],
[0.62768628, 0.37231372],
[0.47559883, 0.52440117],
[0.4267593 , 0.5732407 ],
[0.66172417, 0.33827583],
[0.55092315, 0.44907685],
[0.51749946, 0.48250054],
[0.485743 , 0.514257 ],
[0.49011451, 0.50988549],
[0.52423349, 0.47576651],
[0.61619519, 0.38380481],
[0.52696302, 0.47303698],
[0.63957168, 0.36042832],
[0.52205164, 0.47794836],
[0.50572852, 0.49427148],
[0.70706202, 0.29293798],
[0.55266286, 0.44733714],
[0.52271594, 0.47728406],
[0.51638863, 0.48361137],
[0.71331391, 0.28668609],
[0.67862111, 0.32137889],
[0.50896403, 0.49103597],
[0.42348082, 0.57651918],
[0.71495838, 0.28504162],
[0.59711064, 0.40288936],
[0.63808839, 0.36191161],
[0.39957895, 0.60042105],
[0.52127638, 0.47872362],
[0.65975464, 0.34024536],
[0.5114172 , 0.4885828 ]])