\(𝛽_1,𝛽_2,\dots,𝛽_𝑝\) adalah koefisien dari setiap variabel independen, dan \(𝜖\) adalah error atau residual.
Asumsi Model Model regresi linier berganda membutuhkan beberapa asumsi untuk menghasilkan estimasi yang valid:
Linearitas: Hubungan antara variabel dependen dan independen harus linier. Independensi: Residual harus independen satu sama lain.
Homoskedastisitas: Variansi residual harus konstan di seluruh pengamatan. Normalitas: Residual harus terdistribusi normal.
Tipe-Tipe Regresi Linear di R
library(car)
Loading required package: carData
data("Salaries")head(Salaries)
rank discipline yrs.since.phd yrs.service sex salary
1 Prof B 19 18 Male 139750
2 Prof B 20 16 Male 173200
3 AsstProf B 4 3 Male 79750
4 Prof B 45 39 Male 115000
5 Prof B 40 41 Male 141500
6 AssocProf B 6 6 Male 97000
rank discipline yrs.since.phd yrs.service sex salary Male
1 Prof B 19 18 Male 139750 1
2 Prof B 20 16 Male 173200 1
3 AsstProf B 4 3 Male 79750 1
4 Prof B 45 39 Male 115000 1
5 Prof B 40 41 Male 141500 1
6 AssocProf B 6 6 Male 97000 1
Call:
lm(formula = salary ~ yrs.since.phd + yrs.service + sex_Male,
data = dataf)
Residuals:
Min 1Q Median 3Q Max
-79586 -19564 -3018 15071 105898
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 82875.9 4800.6 17.264 < 2e-16 ***
yrs.since.phd 1552.8 256.1 6.062 3.15e-09 ***
yrs.service -649.8 254.0 -2.558 0.0109 *
sex_Male 8457.1 4656.1 1.816 0.0701 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 27280 on 393 degrees of freedom
Multiple R-squared: 0.1951, Adjusted R-squared: 0.189
F-statistic: 31.75 on 3 and 393 DF, p-value: < 2.2e-16
Pada bagian ini, nilai variabel sex didefinisikan menjadi dummy variabel , di mana kategori Male dan Female diubah menjadi kolom dengan nilai yang tepat.
Sex
Sex_Male
Sex_Female
Male
1
0
Female
0
1
Female
0
1
#tanpa buat dummy variabelmodel3 <-lm(salary~yrs.since.phd + yrs.service + sex, data=Salaries)summary(model3)
Call:
lm(formula = salary ~ yrs.since.phd + yrs.service + sex, data = Salaries)
Residuals:
Min 1Q Median 3Q Max
-79586 -19564 -3018 15071 105898
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 82875.9 4800.6 17.264 < 2e-16 ***
yrs.since.phd 1552.8 256.1 6.062 3.15e-09 ***
yrs.service -649.8 254.0 -2.558 0.0109 *
sexMale 8457.1 4656.1 1.816 0.0701 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 27280 on 393 degrees of freedom
Multiple R-squared: 0.1951, Adjusted R-squared: 0.189
F-statistic: 31.75 on 3 and 393 DF, p-value: < 2.2e-16
Pada bagian ini, nilai variabel sex akan langsung digunakan secara otomatis.
Call:
lm(formula = kesenangan ~ gaji + I(gaji^2) + I(gaji^3), data = datareg)
Residuals:
Min 1Q Median 3Q Max
-7.1251 -1.2526 -0.2991 1.4780 9.4979
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -3.715e+01 1.076e+01 -3.454 0.010639 *
gaji 9.610e+00 1.482e+00 6.486 0.000338 ***
I(gaji^2) -2.022e-01 5.052e-02 -4.001 0.005182 **
I(gaji^3) 9.968e-04 4.949e-04 2.014 0.083855 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 5.289 on 7 degrees of freedom
Multiple R-squared: 0.9748, Adjusted R-squared: 0.964
F-statistic: 90.26 on 3 and 7 DF, p-value: 5.856e-06
#Compare model kuadratik sama kubikanova(modelkuadratik,modelkubik)
Analysis of Variance Table
Model 1: kesenangan ~ gaji + I(gaji^2)
Model 2: kesenangan ~ gaji + I(gaji^2) + I(gaji^3)
Res.Df RSS Df Sum of Sq F Pr(>F)
1 8 309.34
2 7 195.84 1 113.5 4.0567 0.08385 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
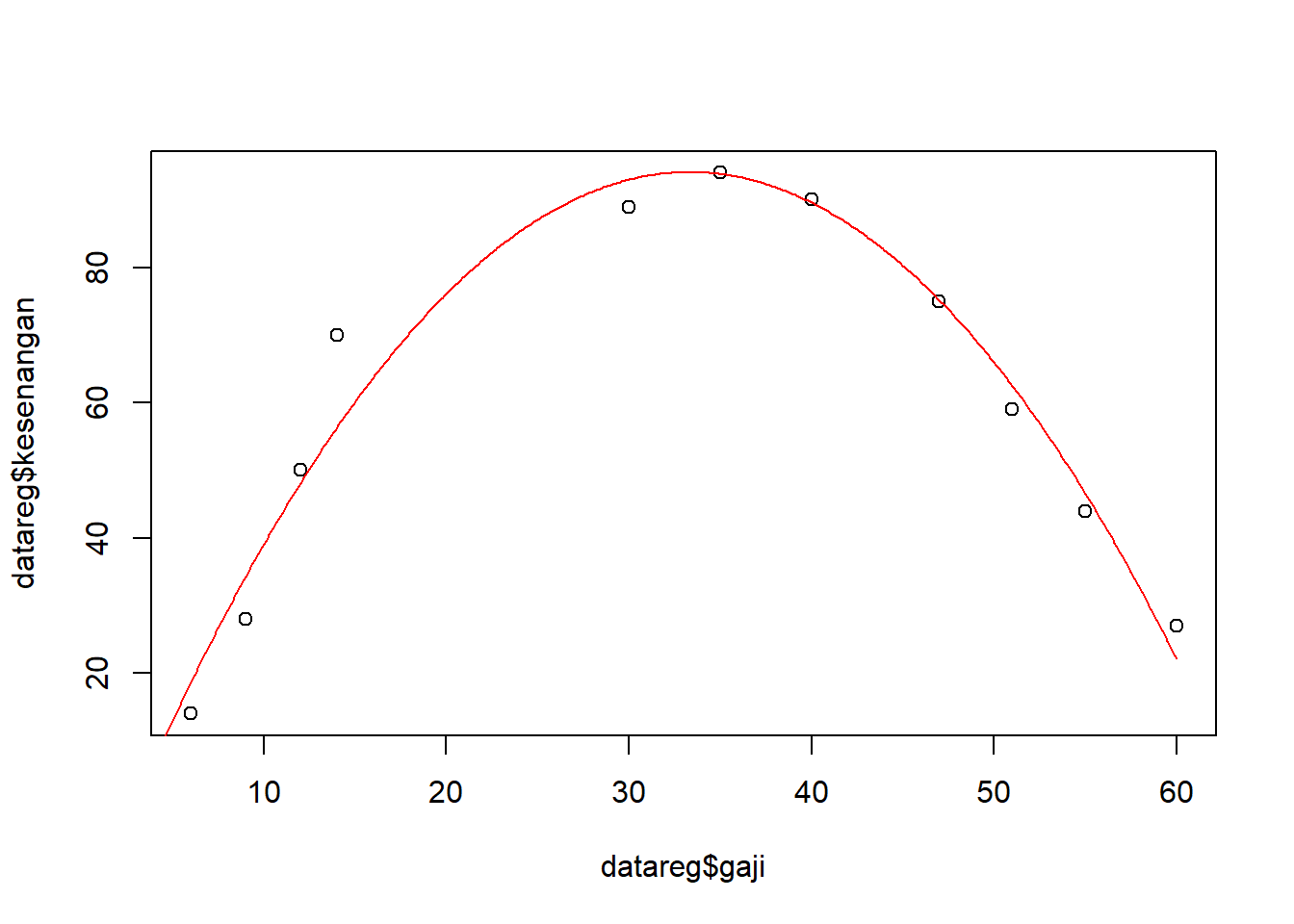
#plot regresi plot(datareg$gaji, datareg$kesenangan)#Mengeluarkan nilai gajinilaigaji <-seq(0, 60, 0.1)#Mengeluarkan nilai prediksi dari model kuadratikpredkesenangan <-predict(modelkuadratik,list(gaji=nilaigaji, gajikuadrat=nilaigaji^2))#Mengeluarkan Plot dengan garislines(nilaigaji, predkesenangan, col='red')
Model Interaksi Interaksi memungkinkan kita untuk menguji apakah efek dari satu variabel independen pada \(𝑌\) dipengaruhi oleh variabel independen lain. Model interaksi dapat dituliskan sebagai:
\[𝑌=𝛽_0 +𝛽_1 𝑋_1 + 𝛽_2𝑋_2 +𝛽_3(𝑋_1×𝑋_2)+𝜖\]
Koefisien \(𝛽_3\) menunjukkan efek interaksi antara \(𝑋_1\) dan \(𝑋_2\) .
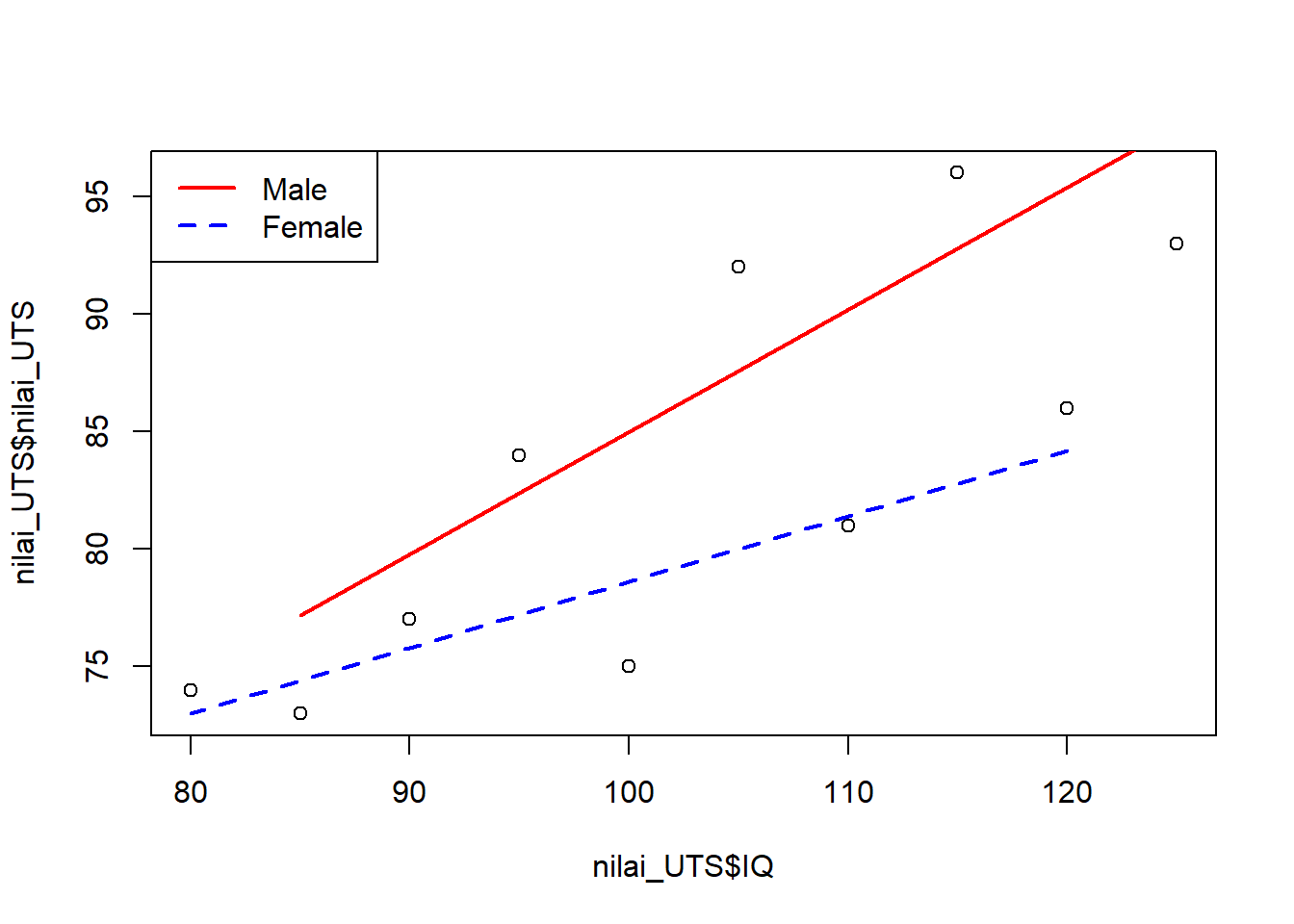
GenderMale <- nilai_UTS[which(nilai_UTS$JenisKelamin=="Male"),]GenderFemale <- nilai_UTS[which(nilai_UTS$JenisKelamin=="Female"),]modelMale <-lm(nilai_UTS ~ IQ, data = GenderMale)modelFemale <-lm(nilai_UTS ~ IQ, data = GenderFemale)#Ngeluarin plot dengan garis plot(nilai_UTS$IQ, nilai_UTS$nilai_UTS)lines(GenderMale$IQ, predict(modelMale), col="red",lty =1 , lwd =2)lines(GenderFemale$IQ, predict(modelFemale), col="blue",lty =2 , lwd =2)legend("topleft", legend=c('Male','Female'), col=c('red','blue'),lty =c(1,2), lwd=c(2,2))
Transformasi Variabel Jika asumsi linearitas atau homoskedastisitas tidak terpenuhi, transformasi variabel dapat membantu. Contoh transformasi yang sering digunakan meliputi:
Logaritma untuk mengatasi ketidakseimbangan skala.
Kuadrat atau akar untuk mengurangi heteroskedastisitas.
Pengujian Model Dalam mengevaluasi model, kita biasanya menggunakan beberapa metrik:
R-squared (\(𝑅^2\) ): Mengukur proporsi variabilitas \(𝑌\) yang dapat dijelaskan oleh model.
Adjusted\(𝑅^2\) : Mengoreksi nilai \(𝑅^2\) dengan mempertimbangkan jumlah variabel independen.
F-Test: Untuk menguji apakah setidaknya satu dari variabel independen berkontribusi signifikan terhadap prediksi \(Y\).
Open Source Exploratory Data
gunakan rawgithubusercontent untuk attrive data langsung secara online.
Poverty, disease, hunger, climate change, war, existential risks, and inequality: the world faces many great and terrifying problems. It is these large problems that our work at Our World in Data focuses on.
This is the data repository for the 2019 Novel Coronavirus Visual Dashboard operated by the Johns Hopkins University Center for Systems Science and Engineering (JHU CSSE). Also, Supported by ESRI Living Atlas Team and the Johns Hopkins University Applied Physics Lab (JHU APL).