Apa Itu Model Building? Model building adalah proses membuat model yang bisa cocok dengan data yang kita miliki dan bisa memberikan prediksi yang baik untuk masa depan. Dalam konteks analisis regresi, ini berarti memilih bentuk model yang bisa menunjukkan hubungan antara hasil yang kita prediksi \((y)\) dan variabel-variabel yang memengaruhi hasil tersebut \((x_1,x_2,...,x_k).\)
Kenapa Proses Ini Penting? Proses model building sangat penting karena menentukan seberapa baik model kita bisa bekerja. Jika model yang kita buat tidak mencerminkan hubungan yang sebenarnya antara variabel-variabel, maka model tersebut tidak akan memberikan hasil yang akurat dan bisa menyebabkan kesalahan dalam analisis atau prediksi.
Langkah-langkah dalam Model Building:
Identifikasi Variabel Respons (Y): Tentukan variabel dependen yang ingin diprediksi atau dianalisis.
Klasifikasi Variabel Prediktor: Kelompokkan variabel independen sebagai variabel kuantitatif (yang diukur dengan angka) atau kualitatif (yang berupa kategori).
Gunakan Dummy Variables: Jika ada variabel kualitatif, ubah variabel tersebut menjadi dummy variables agar bisa dimasukkan ke dalam model.
Pertimbangkan Derajat Lebih Tinggi: Untuk variabel kuantitatif, pertimbangkan untuk menambahkan komponen seperti \(X^2\) atau \(X^3\) untuk menangkap hubungan non-linier yang mungkin ada.
Gunakan Polinomial Derajat Tinggi: Jika relevan, kodekan variabel kuantitatif dalam bentuk polinomial agar model bisa lebih fleksibel dalam menangkap pola data.
Tambahkan Interaksi Antar Variabel: Pertimbangkan untuk menambahkan interaksi antara variabel kuantitatif dan kualitatif untuk melihat efek gabungan mereka terhadap variabel respons.
Bandingkan Model Bertingkat (Nested Models): Gunakan uji partial F-test untuk membandingkan model sederhana dengan model yang lebih kompleks dan pilih model yang terbaik.
Validasi Model: Pastikan model akhir diuji dengan data yang berbeda (misalnya, menggunakan metode cross-validation atau jackknife) untuk memastikan bahwa model tersebut dapat diandalkan untuk prediksi di luar data pelatihan (data training).
Penerapan Model Building
Identifikasi Variabel Respons (Y)
library(AER)
Loading required package: car
Loading required package: carData
Loading required package: lmtest
Loading required package: zoo
Attaching package: 'zoo'
The following objects are masked from 'package:base':
as.Date, as.Date.numeric
Variabel kualitatif yang sudah diubah menjadi faktor di step sebelumnya di-dummy-kan secara otomatis oleh R saat digunakan dalam fungsi lm().
Pertimbangkan Derajat Lebih Tinggi
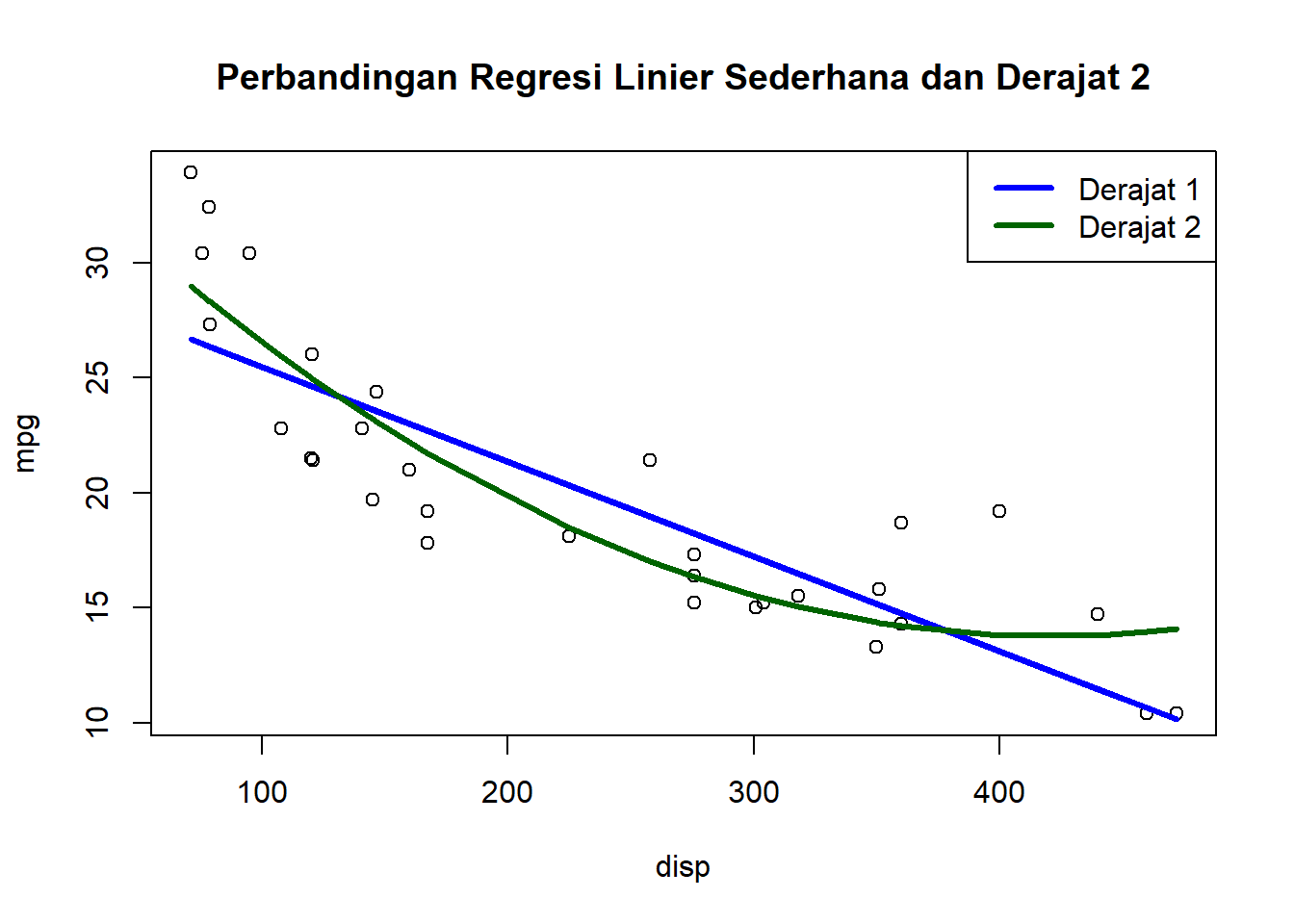
model1 =lm(mpg ~ disp, data = mtcars)model2 =lm(mpg ~ disp +I(disp^2), data = mtcars)
Visualisasi
plot(mtcars$disp, mtcars$mpg, main ='Perbandingan Regresi Linier Sederhana dan Derajat 2', xlab ='disp', ylab ='mpg')lines(mtcars$disp, predict(model1), col ='blue', lwd =3)lines(sort(mtcars$disp), predict(model2)[order(mtcars$disp)], col ='darkgreen', lwd =3)legend('topright', legend =c('Derajat 1', 'Derajat 2'), col =c('blue', 'darkgreen'), lty =1, cex =1, lwd =3)
Tambahkan Interaksi Antar Variabel
model_interaction =lm(mpg ~ disp * hp, data = mtcars)summary(model_interaction)
Call:
lm(formula = mpg ~ disp * hp, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-3.5153 -1.6315 -0.6346 0.9038 5.7030
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.967e+01 2.914e+00 13.614 7.18e-14 ***
disp -7.337e-02 1.439e-02 -5.100 2.11e-05 ***
hp -9.789e-02 2.474e-02 -3.956 0.000473 ***
disp:hp 2.900e-04 8.694e-05 3.336 0.002407 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.692 on 28 degrees of freedom
Multiple R-squared: 0.8198, Adjusted R-squared: 0.8005
F-statistic: 42.48 on 3 and 28 DF, p-value: 1.499e-10
Bandingkan Nested Model
Menggunakan metode seleksi forward, backward, dan both direction.
model_intercept =lm(mpg ~1, data = mtcars)model_full =lm(mpg ~ ., data = mtcars)# Forward selectionforward =step(model_intercept, direction ='forward', scope =formula(model_full), trace =0)summary(forward)
Call:
lm(formula = mpg ~ wt + cyl + hp + am, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-3.9387 -1.2560 -0.4013 1.1253 5.0513
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 33.70832 2.60489 12.940 7.73e-13 ***
wt -2.49683 0.88559 -2.819 0.00908 **
cyl6 -3.03134 1.40728 -2.154 0.04068 *
cyl8 -2.16368 2.28425 -0.947 0.35225
hp -0.03211 0.01369 -2.345 0.02693 *
am1 1.80921 1.39630 1.296 0.20646
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.41 on 26 degrees of freedom
Multiple R-squared: 0.8659, Adjusted R-squared: 0.8401
F-statistic: 33.57 on 5 and 26 DF, p-value: 1.506e-10
# Backward selectionbackward =step(model_full, direction ='backward', trace =0)summary(backward)
Call:
lm(formula = mpg ~ cyl + hp + wt + am, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-3.9387 -1.2560 -0.4013 1.1253 5.0513
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 33.70832 2.60489 12.940 7.73e-13 ***
cyl6 -3.03134 1.40728 -2.154 0.04068 *
cyl8 -2.16368 2.28425 -0.947 0.35225
hp -0.03211 0.01369 -2.345 0.02693 *
wt -2.49683 0.88559 -2.819 0.00908 **
am1 1.80921 1.39630 1.296 0.20646
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.41 on 26 degrees of freedom
Multiple R-squared: 0.8659, Adjusted R-squared: 0.8401
F-statistic: 33.57 on 5 and 26 DF, p-value: 1.506e-10
# Both direction selectionboth =step(model_intercept, direction ='both', scope =formula(model_full), trace =0)summary(both)
Call:
lm(formula = mpg ~ wt + cyl + hp + am, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-3.9387 -1.2560 -0.4013 1.1253 5.0513
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 33.70832 2.60489 12.940 7.73e-13 ***
wt -2.49683 0.88559 -2.819 0.00908 **
cyl6 -3.03134 1.40728 -2.154 0.04068 *
cyl8 -2.16368 2.28425 -0.947 0.35225
hp -0.03211 0.01369 -2.345 0.02693 *
am1 1.80921 1.39630 1.296 0.20646
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.41 on 26 degrees of freedom
Multiple R-squared: 0.8659, Adjusted R-squared: 0.8401
F-statistic: 33.57 on 5 and 26 DF, p-value: 1.506e-10
Validasi Model
Evaluasi model dengan menggunakan metode cross-validation atau melihat pengaruh outliers.
set.seed(123)n <-nrow(mtcars)k <-5# Jumlah foldfolds <-sample(rep(1:k, length.out = n))errors <-numeric(k)for (i in1:k) { train_data <- mtcars[folds != i, ] test_data <- mtcars[folds == i, ] model <-lm(mpg ~ disp + hp + wt, data = train_data) predictions <-predict(model, newdata = test_data) errors[i] <-mean((test_data$mpg - predictions)^2)}mean_cv_error <-mean(errors)print(mean_cv_error)
[1] 9.327748
Nilai mean_cv_error adalah rata-rata dari Mean Squared Error (MSE) pada tiap fold selama cross-validation. Semakin kecil nilainya akan semakin baik, yang berarti model membuat prediksi yang lebih akurat pada data baru. Respectively, nilai yang besar mengindikasikan bahwa model mungkin memiliki masalah, seperti underfitting (model tidak cukup kompleks) atau overfitting (model terlalu kompleks dan tidak mampu melakukan generalisasi dengan baik).
Nilai mean_cv_error sebesar 9 cukup baik atau tidak tergantung pada konteks dan skala data. Jika variabel targte (mpg) dalam dataset mtcars memiliki kisaran nilai yang relatif besar, maka MSE sebesar 9 mungkin dapat diterima. Namun, jika kisaran nilai mpg kecil, maka MSE sebesar 9 bisa dianggap tinggi dan kurang baik yang mengindikasikan model tidak cukup akurat.
Model Validation
Apa Itu Model Validation? Model validation adalah proses mengevaluasi model yang telah dibangun untuk memastikan bahwa model yang dibangun tidak hanya akurat untuk data pelatihan, tetapi juga andal dan stabil saat digunakan pada data lain.
Kenapa Proses Ini Penting? Proses validasi model sangat penting karena memungkinkan kita untuk mengevaluasi ketahanan model saat digunakan pada data baru. Model yang bekerja dengan baik pada data pelatihan mungkin tidak berkinerja sama baiknya pada data yang berbeda, terutama jika model tersebut terlalu “cocok” atau overfit dengan data pelatihan. Validasi ini penting agar model dapat digunakan untuk prediksi atau pengambilan keputusan di dunia nyata tanpa menghasilkan hasil yang bias atau tidak akurat.
Langkah-langkah dalam Model Validation:
Evaluasi Nilai Prediksi: Memeriksa hasil prediksi untuk memastikan bahwa nilainya masuk akal dan tidak menunjukkan pola atau prediksi yang aneh. Ini membantu mendeteksi apakah model menghasilkan prediksi yang valid dan logis.
Pemeriksaan Parameter Model: Mengevaluasi koefisien yang dihasilkan oleh model untuk memastikan bahwa tanda (positif atau negatif) dan besaran koefisien sesuai dengan harapan. Koefisien yang tidak stabil dapat menjadi tanda bahwa model mungkin tidak bekerja baik pada data baru.
Cross-Validation (Data-Splitting): Memisahkan data menjadi data training dan data testing untuk menilai performa model pada data yang tidak dilihat selama pelatihan. Cross-validation mengukur ketahanan model dengan mengevaluasi rata-rata kesalahan prediksi pada data testing.
Jackknifing: Teknik yang digunakan ketika ukuran data terlalu kecil untuk dipecah menjadi data training dan data testing. Metode ini melibatkan penghilangan satu observasi secara bergantian dan menghitung prediksi untuk masing-masing kasus, lalu menganalisis performanya.
Pengumpulan Data Baru untuk Prediksi: Menguji model dengan data baru yang berbeda dari data training Dengan membandingkan prediksi model dengan data nyata yang baru, kita dapat mengukur seberapa baik model bekerja dalam praktik nyata.
Penerapan Model Validation
Membuat Model Regresi
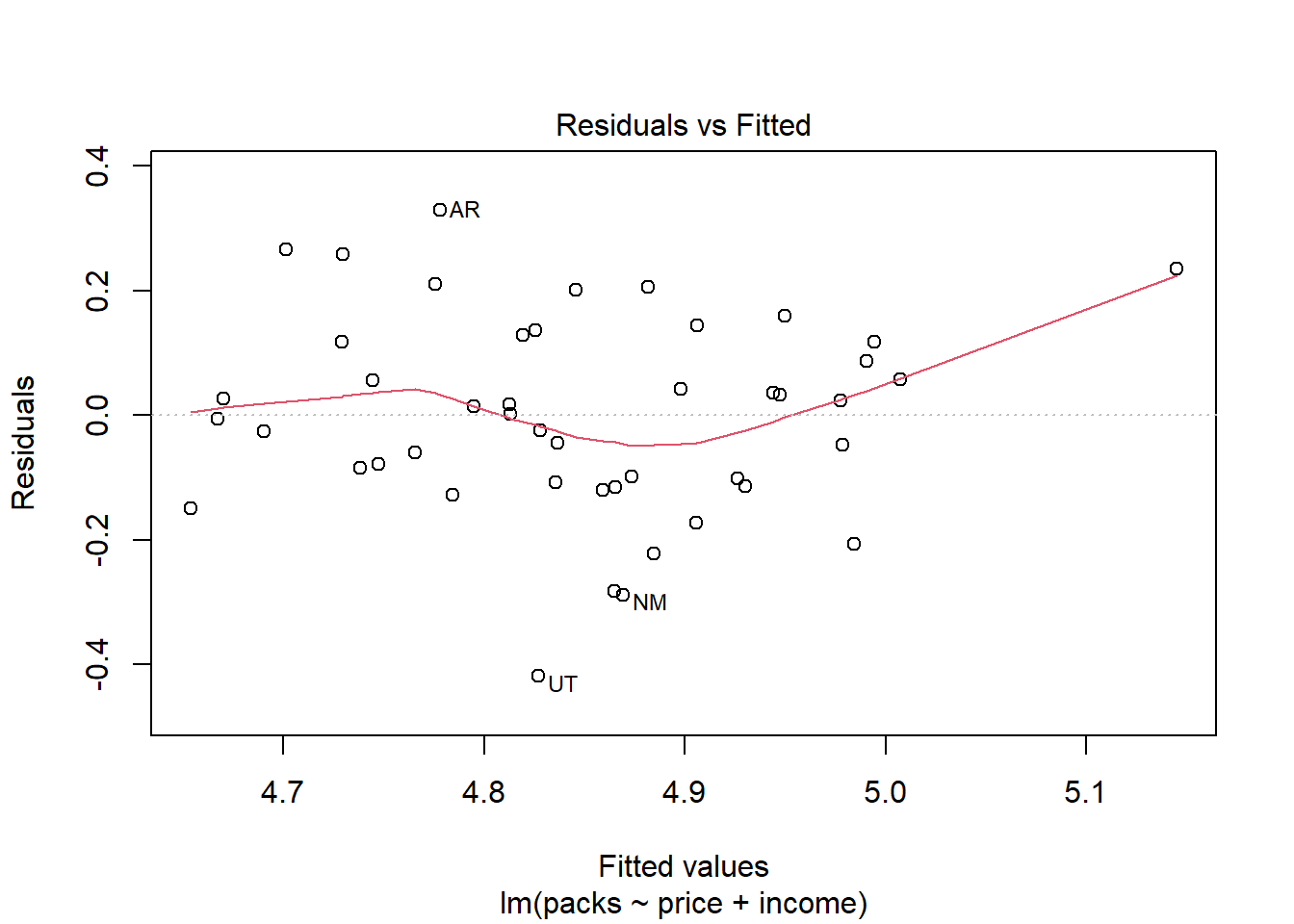
data('CigarettesB')model =lm(packs ~ price + income, data = CigarettesB)summary(model)
Call:
lm(formula = packs ~ price + income, data = CigarettesB)
Residuals:
Min 1Q Median 3Q Max
-0.41867 -0.10683 0.00757 0.11738 0.32868
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.2997 0.9089 4.730 2.43e-05 ***
price -1.3383 0.3246 -4.123 0.000168 ***
income 0.1724 0.1968 0.876 0.385818
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.1634 on 43 degrees of freedom
Multiple R-squared: 0.3037, Adjusted R-squared: 0.2713
F-statistic: 9.378 on 2 and 43 DF, p-value: 0.0004168
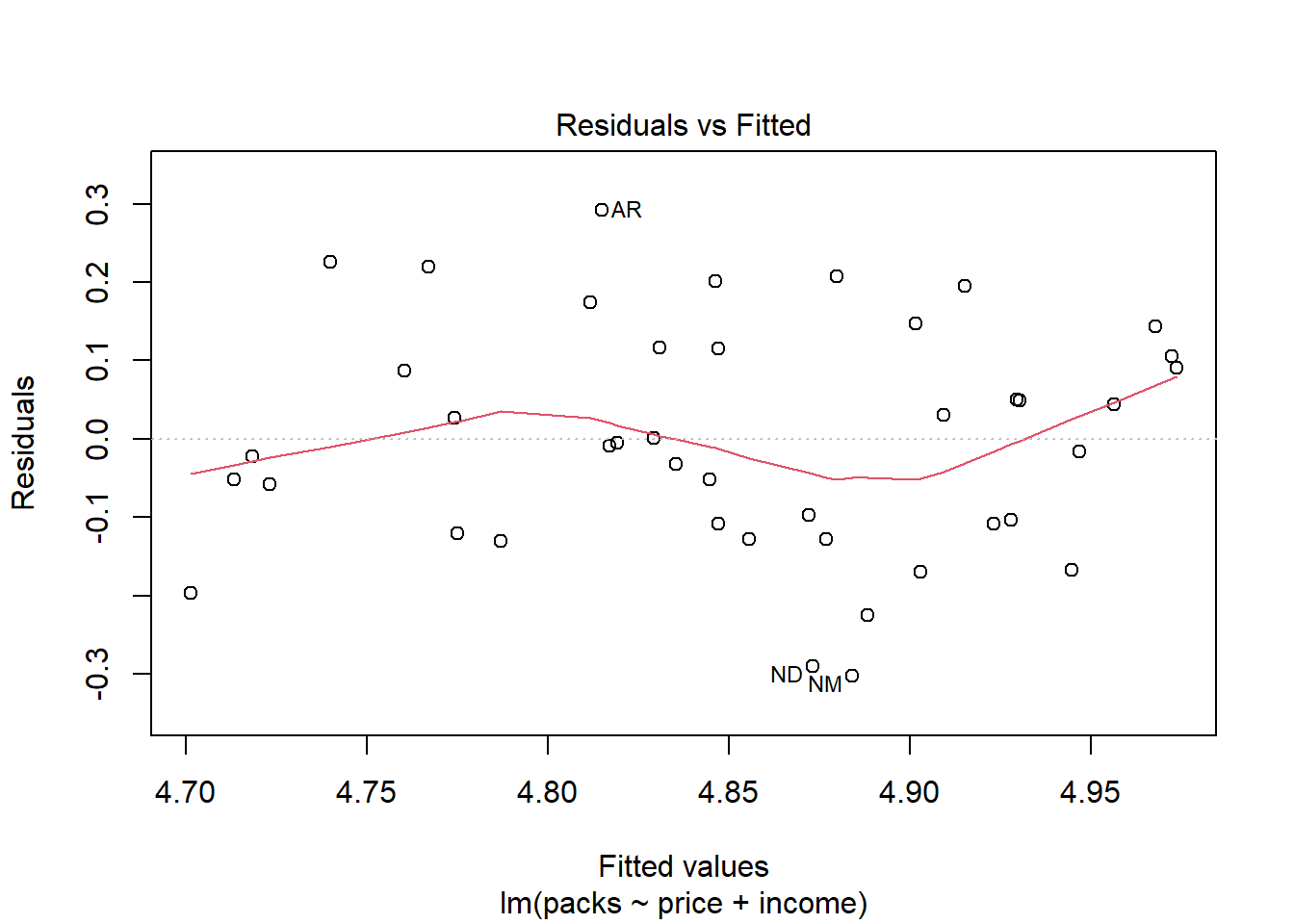
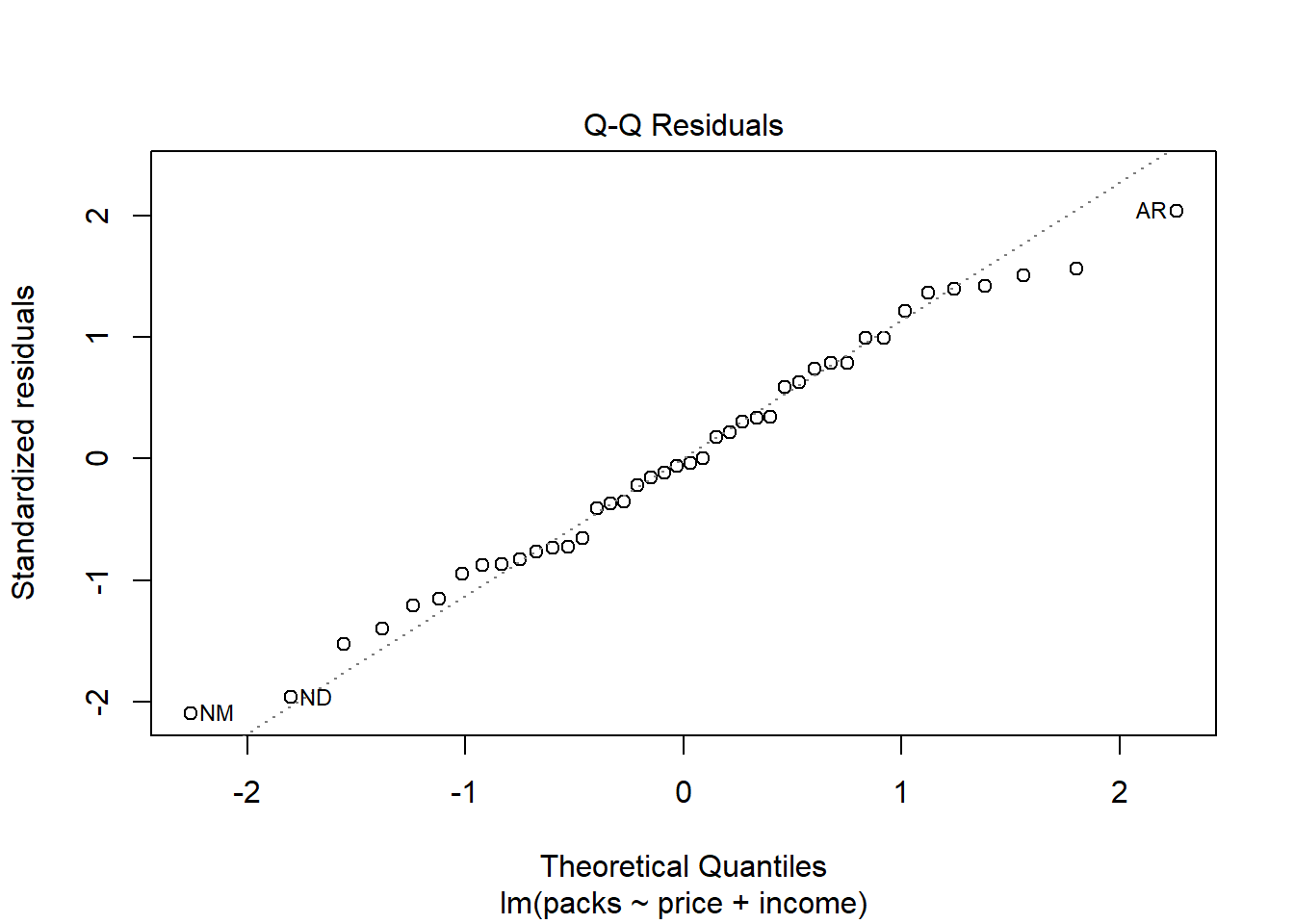
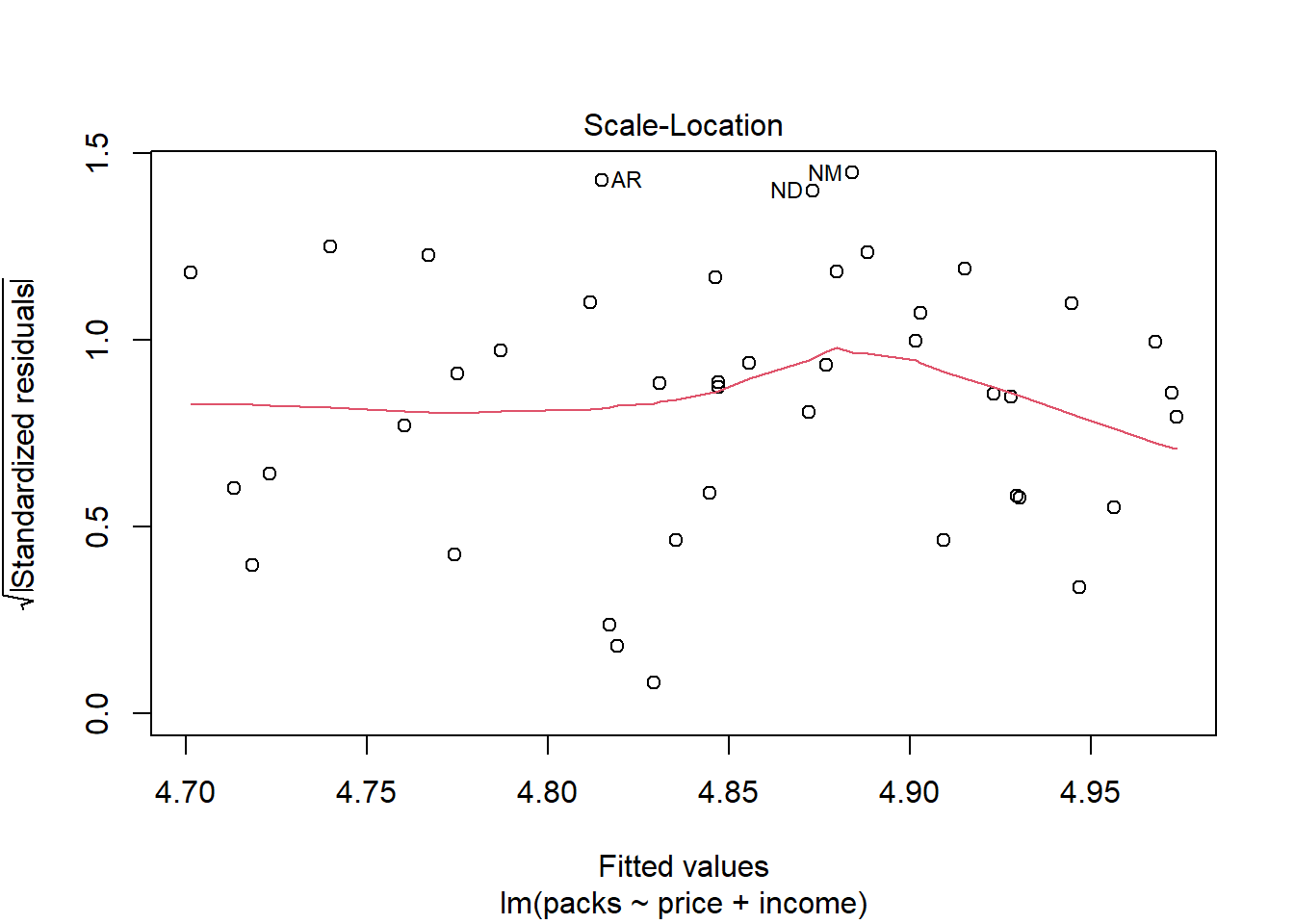
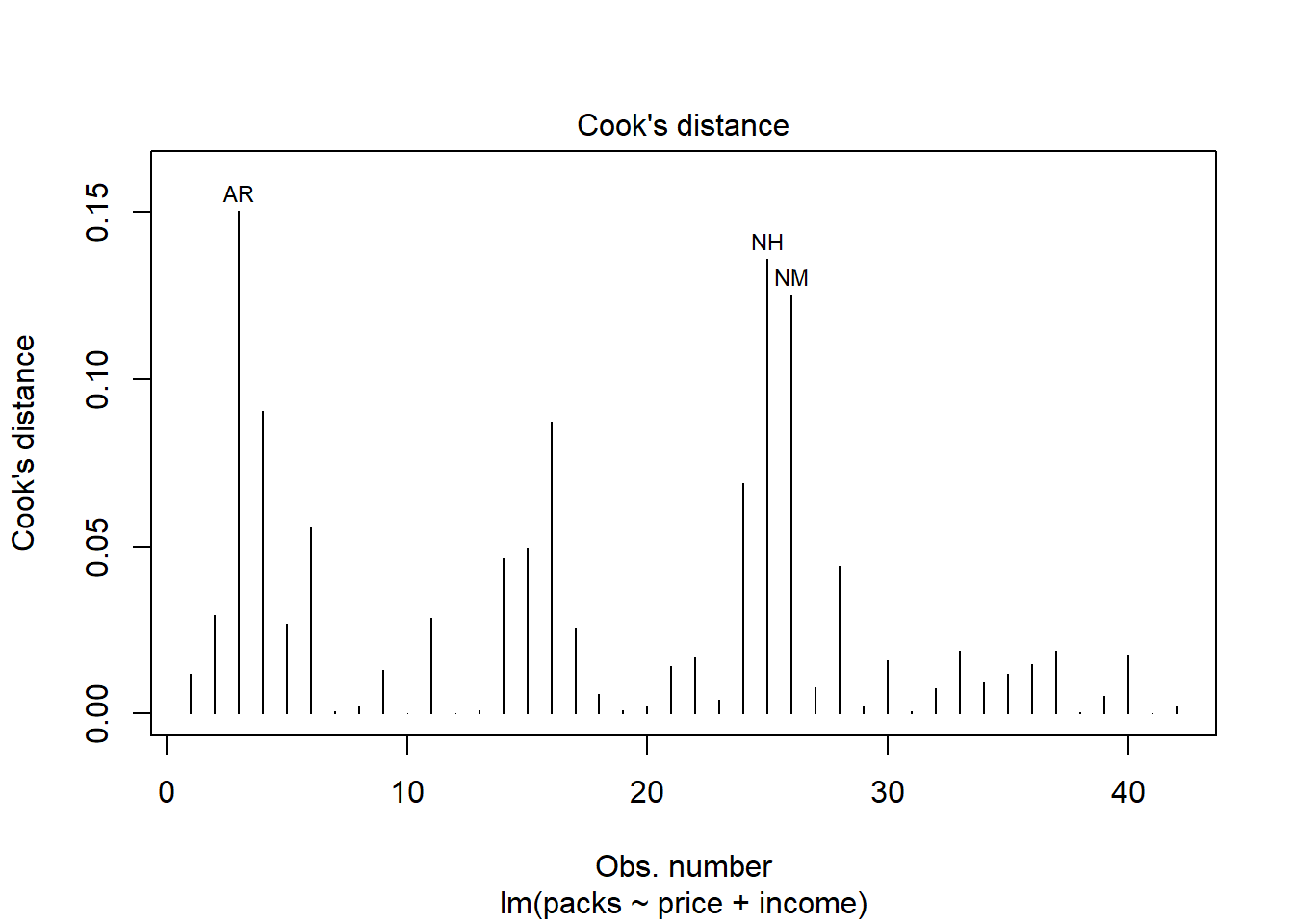
Evaluasi Plot Diagnostik
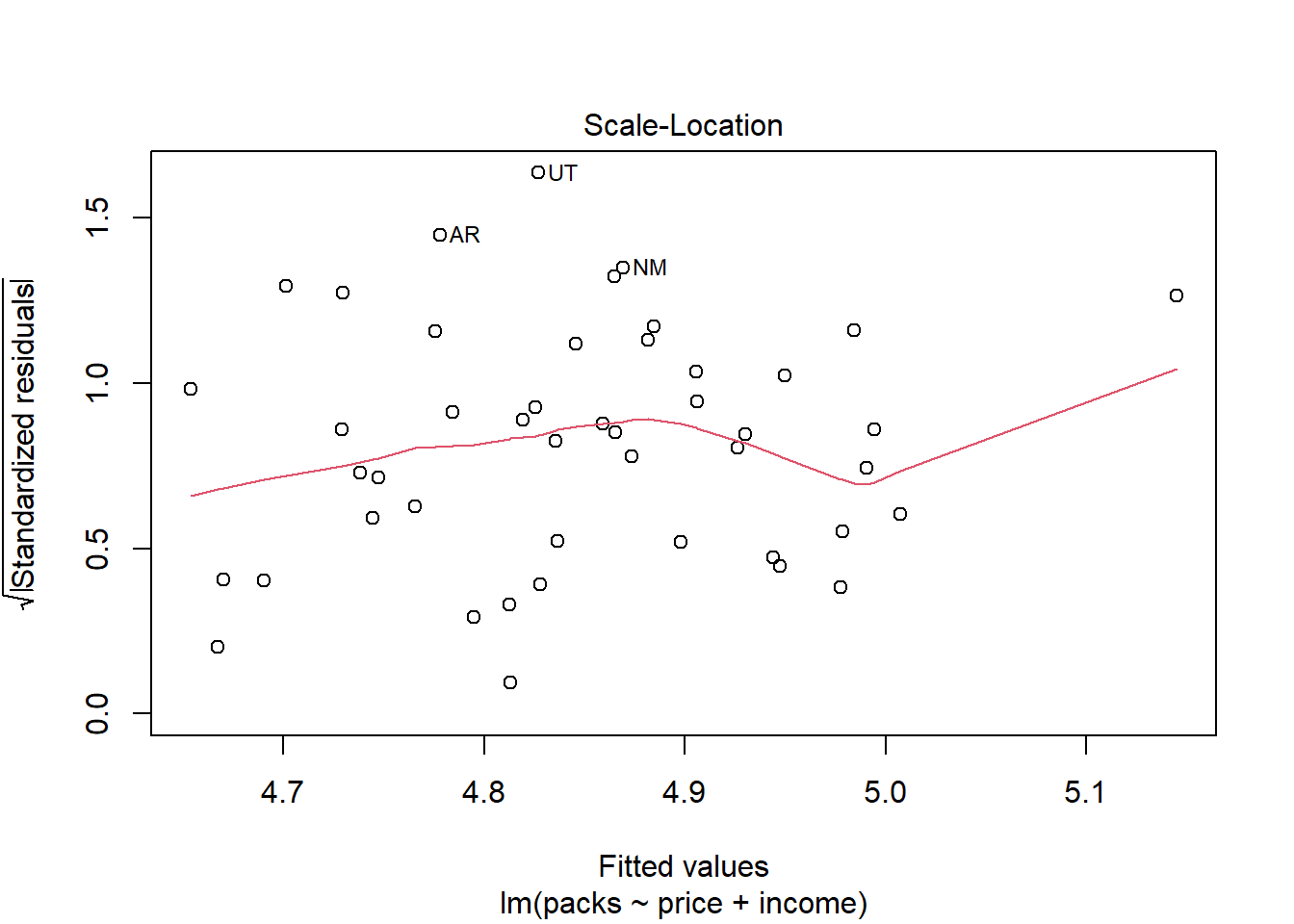
Pada gambar ketiga yang menganalisis pola heteroskedastisitas pada model menunjukkan bahwa meskipun titik-titik tidak sepenuhnya mengikuti garis horizontal dengan distribusi yang merata, plot ini menunjukkan adanya potensi heteroskedastisitas dalam model.
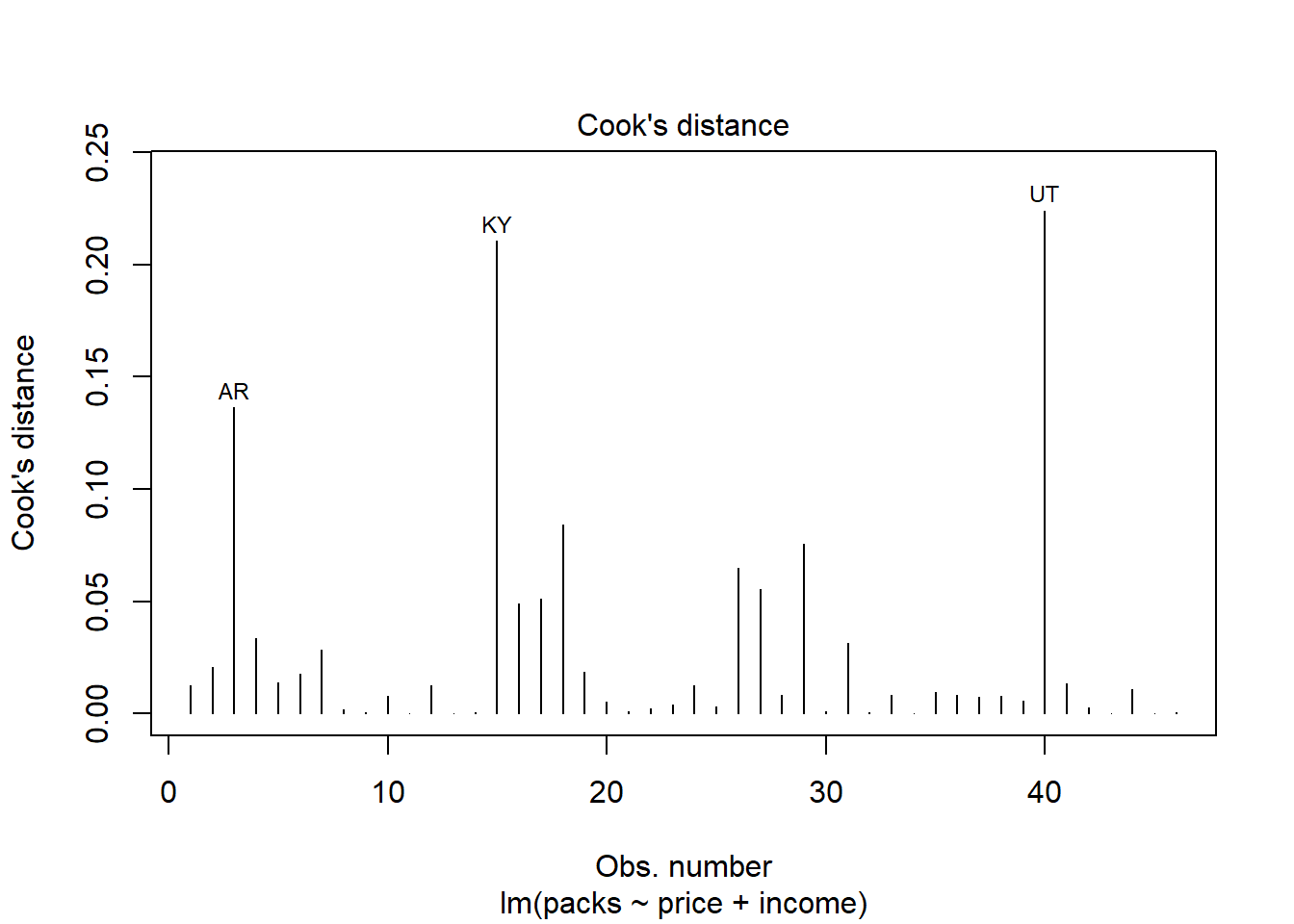
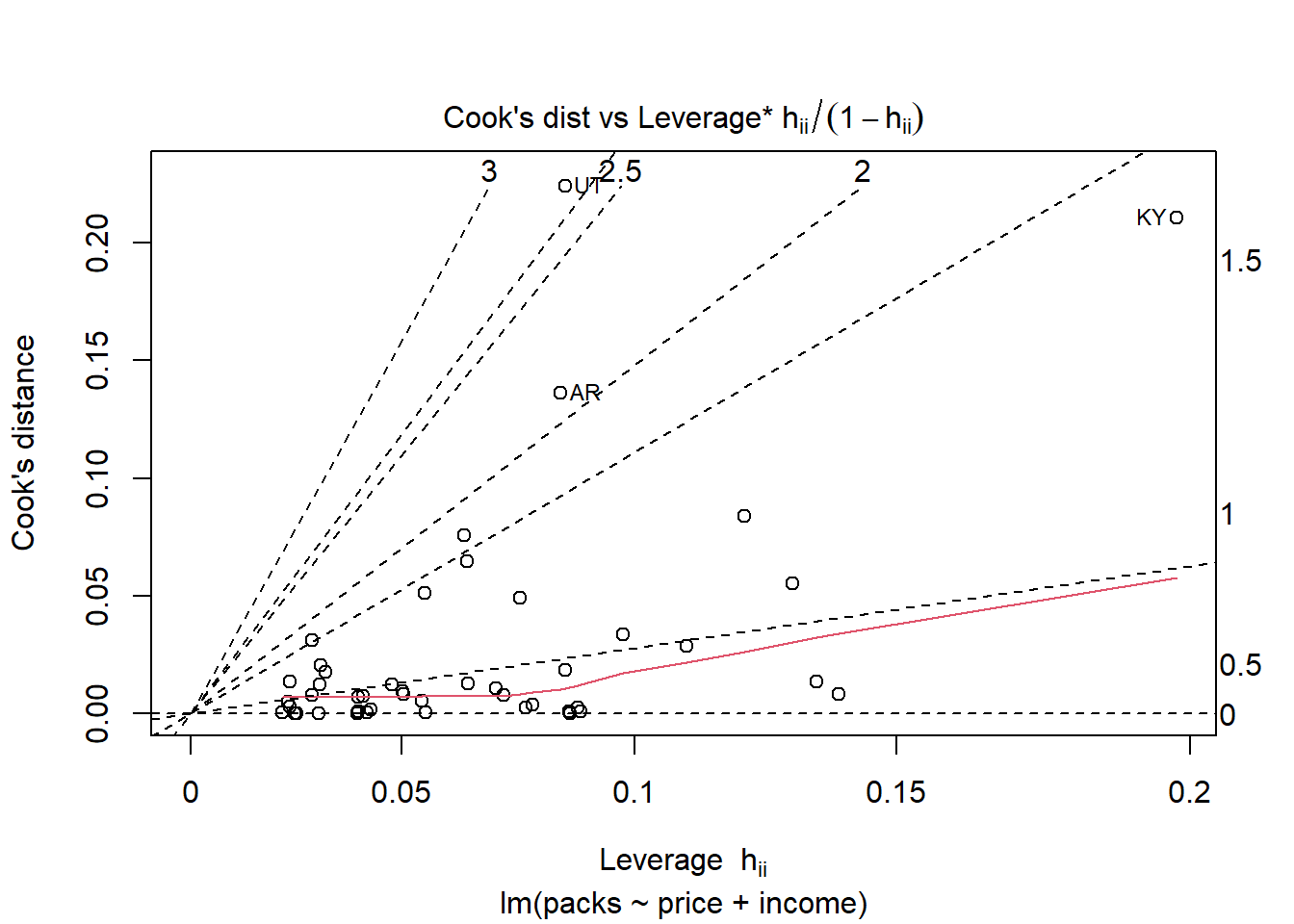
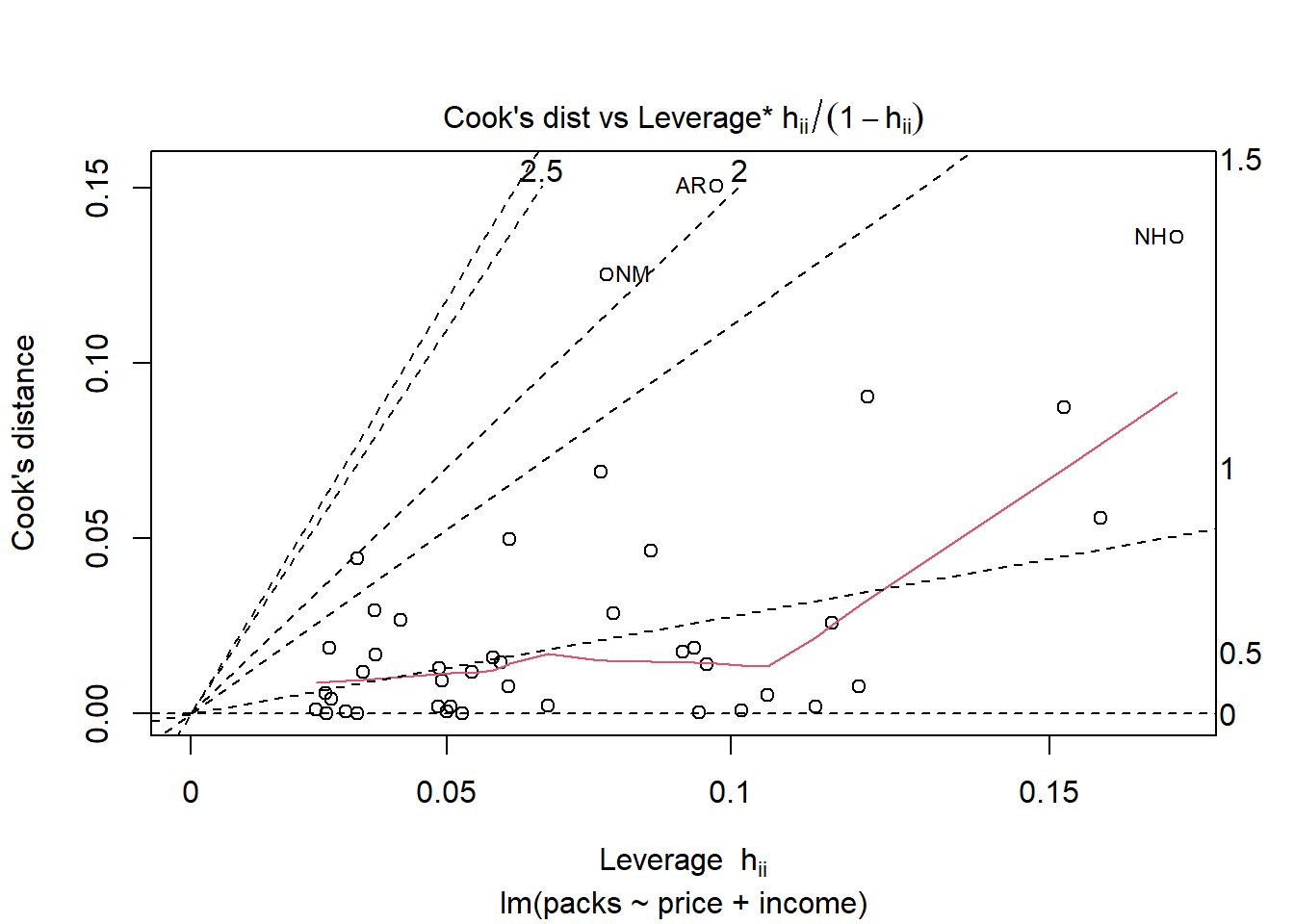
Plot keempat yang merupakan plot Cook’s distance digunakan untuk mengidentifikasi pengamatan (observasi) yang memiliki pengaruh besar terhadap model regresi. Pengamatan dengan nilai Cook’s Distance yang tinggi menunjukkan bahwa mereka memiliki dampak signifikan terhadap koefisien regresi dan mungkin menjadi outlier atau pengamatan berpengaruh. Pengamatan UT memiliki Cook’s Distance tertinggi, menunjukkan bahwa ini adalah pengamatan paling berpengaruh dalam model. AR dan KY juga menunjukkan nilai yang cukup tinggi, yang berarti mereka juga mempengaruhi hasil regresi.
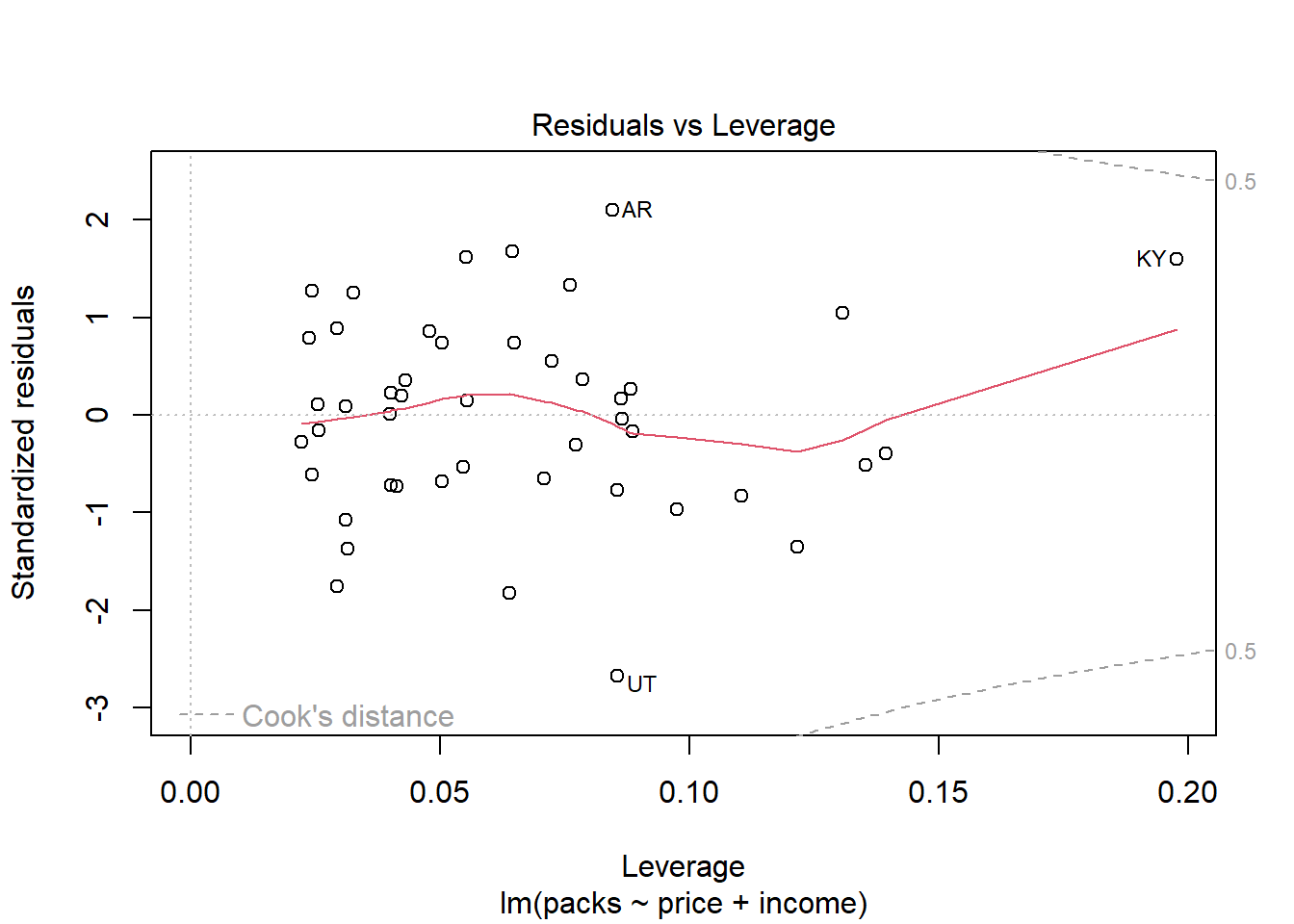
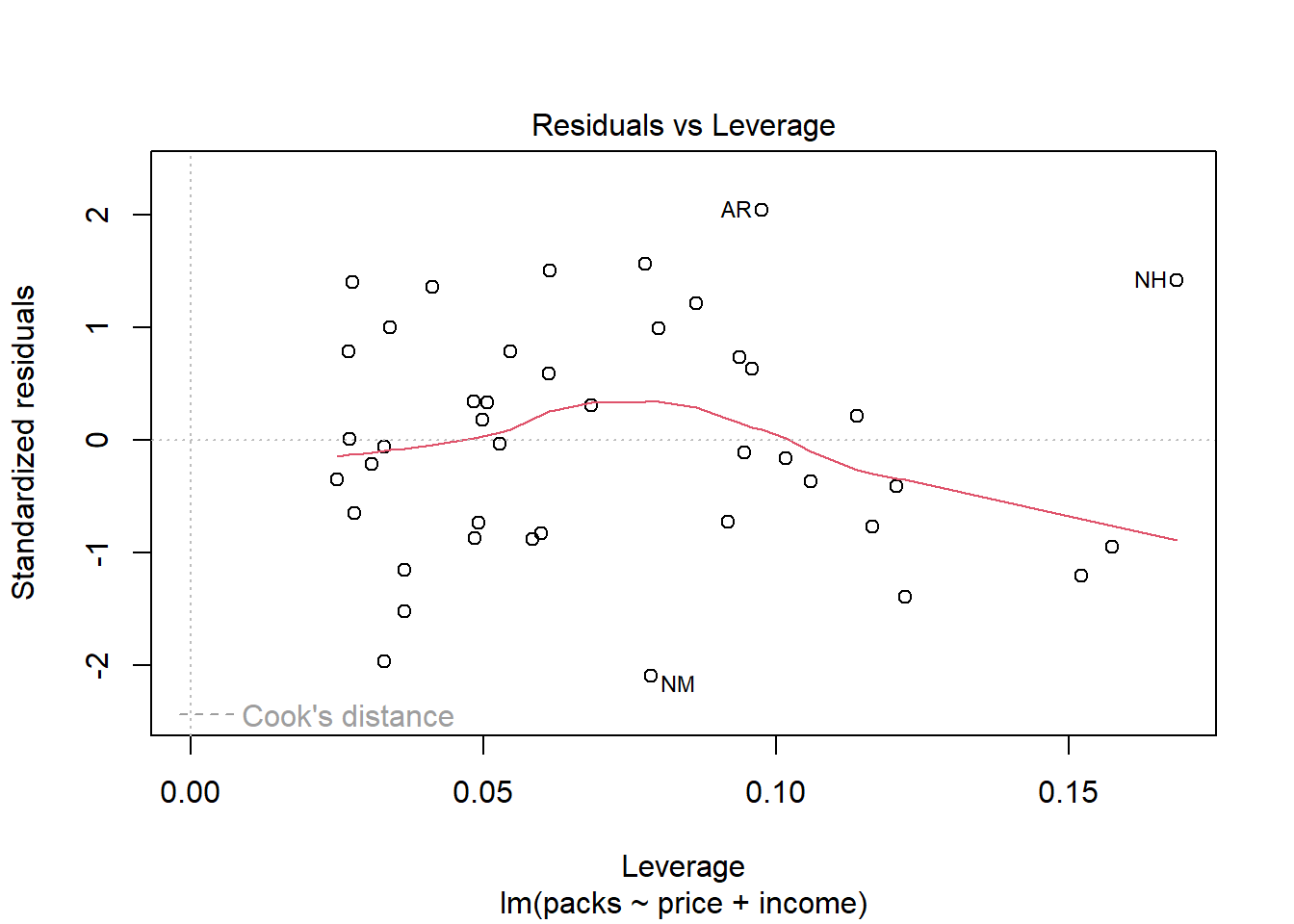
Plot Residuals vs Leverage digunakan untuk mengidentifikasi pengamatan yang memiliki leverage tinggi (pengaruh besar pada model) dan residual yang besar (outliers). Garis melengkung (Cook’s Distance) membantu menilai seberapa besar pengaruh pengamatan terhadap model. Pengamatan KY perlu diperiksa lebih lanjut untuk menentukan apakah ada alasan sah untuk pengaruhnya yang besar. Jika pengaruh ini tidak dapat dijustifikasi, dapat dipertimbangkan untuk memodifikasi model atau menghapus pengamatan tersebut. Pengamatan lainnya seperti AR dan UT perlu dipertimbangkan, tetapi perhatian utama harus diberikan pada pengamatan dengan leverage tinggi seperti KY.
plot(model, which =1:6)
Deteksi Observasi Berpengaruh (Leverage dan Cook’s Distance)
dfb.1_, dfb.pric, dfb.incm disebut dengan DFBETAS, yang mengukur pengaruh pengamatan individu pada koefisien regresi. Menunjukkan seberapa besar koefisien regresi akan berubah jika pengamatan tersebut dihapus.
dffit disebut DFITS, yaitu ukuran seberapa besar pengaruh pengamatan terhadap prediksi model. Nilai dffit yang besar (lebih dari +-2*sqrt(p/n). => Pengamatan KY dan UT memiliki nilai dffit yang signifikan (ditandai dengan *_) mengindikasikan bahwa mereka mempengaruhi prediksi model secara substansial.
cov.r merupakan rasio covariance yang mengukur stabilitas covariance dari parameter model ketika pengamatan dihapus. Nilai cov.r yang jauh dari 1 menunjukkan adanya pengaruh besar dari pengamatan tersebut => UT memiliki nilai cov.r yang lebih rendah dari 1 (0.68_*) yang mengindikasikan bahwa pengamatan ini mempengaruhi stabilitas model secara signifikan.
cook.d merupakan Cook’s Distance yang merupakan ukuran keseluruhan pengaruh pengamatan pada model regresi. KY dan UT memiliki nilai cook.d cukup tinggi (0.21 dan 0.22) menunjukkan bahwa mereka memiliki pengaruh signifikan terhadap hasil model.
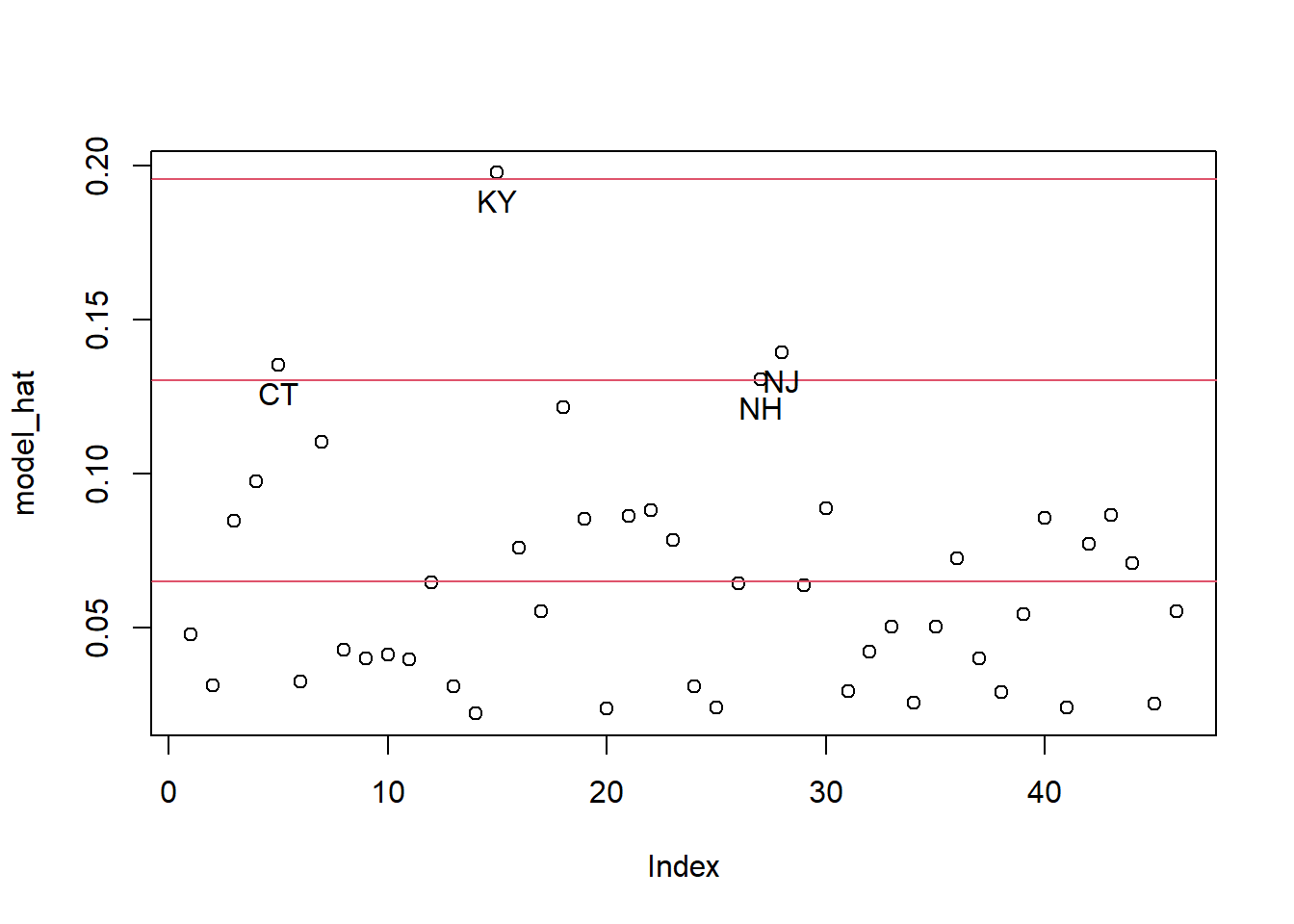
hat (leverage) mengukur seberapa jauh pengamatan tertentu dari nilai rata-rata variabel prediktor. KY memiliki leverage tinggi (0.20_*) yang berarti pengamatan ini jauh dari nilai rata-rata variabel independen dan dapat mempengaruhi hasil model.