2+3[1] 57-5[1] 23*5[1] 153/4[1] 0.752:4[1] 2 3 42**3 # pangkat[1] 8R: Basic Operations, Descriptive Statistics, Frequency Visualizations
Kembali ke Pengantar Sains Data
Untuk pertemuan kali ini, kita akan mulai membahas lebih lanjut tentang penggunaan bahasa R, melalui RStudio.
Dataset “Iris” yang digunakan di modul ini bisa langsung diakses melalui R, atau bisa juga diunduh:
Kebetulan, materi modul kali ini adalah revisi dari modul PSD tahun lalu. Silakan intip kalau mau :)
Silakan buka RStudio dulu, ya! Gunakan perangkat (laptop atau komputer) yang sudah terinstal R dan RStudio. Kalau perlu, petunjuk instalasi ada di modul pertemuan pertama.
Sebelum mulai menggunakan R dengan RStudio, jangan lupa untuk membuat file baru .R dan disimpan. Pencet File > New File > R Script untuk membuat, lalu tekan Ctrl + S (Windows) atau Cmd + S (macOS) untuk menyimpan. Silakan pilih dan/atau buat folder untuk menyimpan file tersebut.
Jangan lupa menyimpan file secara berkala (juga dengan Ctrl + S atau Cmd + S) agar tidak hilang.
Suatu file .R bisa terdiri dari sejumlah baris kode berbahasa R.
Tiap baris bisa dijalankan masing-masing, dengan cara menekan baris tersebut, kemudian memencet tombol Ctrl dan Enter sekaligus di keyboard (atau biasa ditulis Ctrl + Enter) untuk Windows, atau Cmd + Enter untuk macOS.
Apabila ingin menjalankan beberapa baris sekaligus, select dulu (dengan mouse) baris-baris yang ingin dijalankan, baru tekan Ctrl + Enter (Windows) atau Cmd + Enter (macOS).
Kalau mau (jarang digunakan), keseluruhan file .R bisa dijalankan dengan Ctrl + Shift + Enter (Windows) atau Cmd + Shift + Enter (macOS).
Kita review pengenalan R dari pertemuan pertama dulu, ya!
Kalian bisa mengetik kemudian mencoba menjalankan masing-masing baris kode berikut, untuk perhitungan dasar di R. Apabila menggunakan RStudio, hasilnya akan muncul di bagian bawah, yang disebut “Console”. (Sebenarnya, daripada mengetik di file, kalian bisa saja langsung mengetik kode di Console, tetapi tidak bisa disimpan.)
2+3[1] 57-5[1] 23*5[1] 153/4[1] 0.752:4[1] 2 3 42**3 # pangkat[1] 8Pendefinisian variabel di R bisa menggunakan <- (lebih umum digunakan) atau menggunakan = seperti berikut:
apel <- 4
jeruk = 7Ruas kiri merupakan nama variabel dan ruas kanan merupakan nilai variabel.
Untuk memanggil (memeriksa isi) suatu variabel, cukup ketik namanya, lalu jalankan:
apel[1] 4Lebih jelasnya, bisa menggunakan fungsi print seperti berikut:
print(apel)[1] 4Variabel juga bisa diterapkan operasi dasar, misalnya seperti berikut:
apel-jeruk[1] -3apel*jeruk[1] 28Kita juga bisa mendefinisikan variabel baru menggunakan nilai dari variabel yang sudah ada:
banyakbuah <- jeruk+apel
banyakbuah[1] 11Untuk melihat semua variabel yang sudah ada,
di tampilan RStudio, cukup lihat bagian “Environment” yang harusnya ada di sebelah kanan layar. Terlihat nama tiap variabel yang sudah terdefinisi, beserta nilai masing-masing.
secara pemrograman R, bisa dengan fungsi atau perintah ls()
ls()[1] "apel" "banyakbuah" "jeruk" Di R, kita juga bisa menghapus variabel, menggunakan fungsi atau perintah rm()
rm(banyakbuah)Kalau kita coba panggil banyakbuah lagi, akan error.
Apabila ingin menghapus semua variabel, kita bisa memberikan daftar semua variabel yang ada (yaitu hasil ls()) ke rm() seperti berikut:
rm(list=ls())Sebelumnya, kita sudah mengenal variabel yang bisa menyimpan data, seperti data numerik, juga data teks atau string.
Apabila kita ingin menuliskan sekumpulan data, di R ada konsep vector, yang seperti array di pemrograman pada umumnya. Kita bisa menggabungkan sejumlah data agar menjadi satu kesatuan dengan fungsi c() atau combine, misalnya sebagai berikut:
angka <- c(1, 2, 3)
print(angka)[1] 1 2 3nama_buah <- c("apel", "jeruk", "pisang")
print(nama_buah)[1] "apel" "jeruk" "pisang"Kita juga bisa melakukan sampling, yaitu mengambil sekian buah data secara sembarang, seperti berikut. Coba jalankan beberapa kali, hasilnya kemungkinan akan berbeda-beda, tetapi tidak mungkin hal yang sama dipilih lebih dari sekali.
sample(nama_buah, 2)[1] "jeruk" "pisang"sample(nama_buah, 2)[1] "pisang" "jeruk" sample(nama_buah, 2)[1] "jeruk" "apel" Sampling seperti itu disebut tanpa pengembalian (without replacement). Apabila angka 2 diganti jadi angka 4, kita memerintah R untuk mengambil 4 buah data yang tidak boleh sama dari suatu vector yang hanya memiliki 3 buah data, sehingga akan error.
Sebenarnya, di R, kita juga bisa melakukan sampling dengan pengembalian (with replacement), dengan tambahan opsi replace = TRUE sebagai berikut. Apabila dijalankan berkali-kali, hasilnya juga kemungkinan akan berbeda-beda, tetapi buah yang sama bisa dipilih lebih dari sekali.
sample(nama_buah, 4, replace = TRUE)[1] "pisang" "jeruk" "apel" "pisang"sample(nama_buah, 4, replace = TRUE)[1] "apel" "pisang" "jeruk" "pisang"sample(nama_buah, 4, replace = TRUE)[1] "jeruk" "jeruk" "jeruk" "apel" Apabila kalian coba replace = FALSE, hasilnya akan seolah-olah kalian tidak menentukan opsi replace sama sekali.
Sekumpulan data biasa disebut dataset. Di R, ada sejumlah dataset yang built-in, yaitu “sudah ada dari sananya”. Di antara itu, dataset paling terkenal adalah iris, yaitu data tiga spesies bunga Iris, yang sering digunakan dalam pengantar statistika (seperti mata kuliah PSD ini) ataupun pengantar machine learning.
Kita bisa mengaktifkan dataset iris tersebut dengan perinah berikut, menggunakan string:
data("iris")Sebagaimana di Python, penulisan string di R juga bebas antara menggunakan tanda petik 'seperti ini' ataupun tanda kutip "seperti ini", yang penting konsisten.
Setelah menjalankan kode di atas, dataset iris sudah diaktifkan. Untuk melihatnya,
di RStudio, lihat ke bagian Environment. Kalian bisa double click atau klik dua kali tulisan iris agar muncul tab baru berisi tabelnya.
secara pemrograman, kalian bisa mengetik iris begitu saja sebagaimana ketika ingin menampilkan variabel, seperti berikut. Kemudian, tampilan tabel untuk dataset iris akan muncul di Console (bisa di-scroll).
iris Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5.0 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosa
11 5.4 3.7 1.5 0.2 setosa
12 4.8 3.4 1.6 0.2 setosa
13 4.8 3.0 1.4 0.1 setosa
14 4.3 3.0 1.1 0.1 setosa
15 5.8 4.0 1.2 0.2 setosa
16 5.7 4.4 1.5 0.4 setosa
17 5.4 3.9 1.3 0.4 setosa
18 5.1 3.5 1.4 0.3 setosa
19 5.7 3.8 1.7 0.3 setosa
20 5.1 3.8 1.5 0.3 setosa
21 5.4 3.4 1.7 0.2 setosa
22 5.1 3.7 1.5 0.4 setosa
23 4.6 3.6 1.0 0.2 setosa
24 5.1 3.3 1.7 0.5 setosa
25 4.8 3.4 1.9 0.2 setosa
26 5.0 3.0 1.6 0.2 setosa
27 5.0 3.4 1.6 0.4 setosa
28 5.2 3.5 1.5 0.2 setosa
29 5.2 3.4 1.4 0.2 setosa
30 4.7 3.2 1.6 0.2 setosa
31 4.8 3.1 1.6 0.2 setosa
32 5.4 3.4 1.5 0.4 setosa
33 5.2 4.1 1.5 0.1 setosa
34 5.5 4.2 1.4 0.2 setosa
35 4.9 3.1 1.5 0.2 setosa
36 5.0 3.2 1.2 0.2 setosa
37 5.5 3.5 1.3 0.2 setosa
38 4.9 3.6 1.4 0.1 setosa
39 4.4 3.0 1.3 0.2 setosa
40 5.1 3.4 1.5 0.2 setosa
41 5.0 3.5 1.3 0.3 setosa
42 4.5 2.3 1.3 0.3 setosa
43 4.4 3.2 1.3 0.2 setosa
44 5.0 3.5 1.6 0.6 setosa
45 5.1 3.8 1.9 0.4 setosa
46 4.8 3.0 1.4 0.3 setosa
47 5.1 3.8 1.6 0.2 setosa
48 4.6 3.2 1.4 0.2 setosa
49 5.3 3.7 1.5 0.2 setosa
50 5.0 3.3 1.4 0.2 setosa
51 7.0 3.2 4.7 1.4 versicolor
52 6.4 3.2 4.5 1.5 versicolor
53 6.9 3.1 4.9 1.5 versicolor
54 5.5 2.3 4.0 1.3 versicolor
55 6.5 2.8 4.6 1.5 versicolor
56 5.7 2.8 4.5 1.3 versicolor
57 6.3 3.3 4.7 1.6 versicolor
58 4.9 2.4 3.3 1.0 versicolor
59 6.6 2.9 4.6 1.3 versicolor
60 5.2 2.7 3.9 1.4 versicolor
61 5.0 2.0 3.5 1.0 versicolor
62 5.9 3.0 4.2 1.5 versicolor
63 6.0 2.2 4.0 1.0 versicolor
64 6.1 2.9 4.7 1.4 versicolor
65 5.6 2.9 3.6 1.3 versicolor
66 6.7 3.1 4.4 1.4 versicolor
67 5.6 3.0 4.5 1.5 versicolor
68 5.8 2.7 4.1 1.0 versicolor
69 6.2 2.2 4.5 1.5 versicolor
70 5.6 2.5 3.9 1.1 versicolor
71 5.9 3.2 4.8 1.8 versicolor
72 6.1 2.8 4.0 1.3 versicolor
73 6.3 2.5 4.9 1.5 versicolor
74 6.1 2.8 4.7 1.2 versicolor
75 6.4 2.9 4.3 1.3 versicolor
76 6.6 3.0 4.4 1.4 versicolor
77 6.8 2.8 4.8 1.4 versicolor
78 6.7 3.0 5.0 1.7 versicolor
79 6.0 2.9 4.5 1.5 versicolor
80 5.7 2.6 3.5 1.0 versicolor
81 5.5 2.4 3.8 1.1 versicolor
82 5.5 2.4 3.7 1.0 versicolor
83 5.8 2.7 3.9 1.2 versicolor
84 6.0 2.7 5.1 1.6 versicolor
85 5.4 3.0 4.5 1.5 versicolor
86 6.0 3.4 4.5 1.6 versicolor
87 6.7 3.1 4.7 1.5 versicolor
88 6.3 2.3 4.4 1.3 versicolor
89 5.6 3.0 4.1 1.3 versicolor
90 5.5 2.5 4.0 1.3 versicolor
91 5.5 2.6 4.4 1.2 versicolor
92 6.1 3.0 4.6 1.4 versicolor
93 5.8 2.6 4.0 1.2 versicolor
94 5.0 2.3 3.3 1.0 versicolor
95 5.6 2.7 4.2 1.3 versicolor
96 5.7 3.0 4.2 1.2 versicolor
97 5.7 2.9 4.2 1.3 versicolor
98 6.2 2.9 4.3 1.3 versicolor
99 5.1 2.5 3.0 1.1 versicolor
100 5.7 2.8 4.1 1.3 versicolor
101 6.3 3.3 6.0 2.5 virginica
102 5.8 2.7 5.1 1.9 virginica
103 7.1 3.0 5.9 2.1 virginica
104 6.3 2.9 5.6 1.8 virginica
105 6.5 3.0 5.8 2.2 virginica
106 7.6 3.0 6.6 2.1 virginica
107 4.9 2.5 4.5 1.7 virginica
108 7.3 2.9 6.3 1.8 virginica
109 6.7 2.5 5.8 1.8 virginica
110 7.2 3.6 6.1 2.5 virginica
111 6.5 3.2 5.1 2.0 virginica
112 6.4 2.7 5.3 1.9 virginica
113 6.8 3.0 5.5 2.1 virginica
114 5.7 2.5 5.0 2.0 virginica
115 5.8 2.8 5.1 2.4 virginica
116 6.4 3.2 5.3 2.3 virginica
117 6.5 3.0 5.5 1.8 virginica
118 7.7 3.8 6.7 2.2 virginica
119 7.7 2.6 6.9 2.3 virginica
120 6.0 2.2 5.0 1.5 virginica
121 6.9 3.2 5.7 2.3 virginica
122 5.6 2.8 4.9 2.0 virginica
123 7.7 2.8 6.7 2.0 virginica
124 6.3 2.7 4.9 1.8 virginica
125 6.7 3.3 5.7 2.1 virginica
126 7.2 3.2 6.0 1.8 virginica
127 6.2 2.8 4.8 1.8 virginica
128 6.1 3.0 4.9 1.8 virginica
129 6.4 2.8 5.6 2.1 virginica
130 7.2 3.0 5.8 1.6 virginica
131 7.4 2.8 6.1 1.9 virginica
132 7.9 3.8 6.4 2.0 virginica
133 6.4 2.8 5.6 2.2 virginica
134 6.3 2.8 5.1 1.5 virginica
135 6.1 2.6 5.6 1.4 virginica
136 7.7 3.0 6.1 2.3 virginica
137 6.3 3.4 5.6 2.4 virginica
138 6.4 3.1 5.5 1.8 virginica
139 6.0 3.0 4.8 1.8 virginica
140 6.9 3.1 5.4 2.1 virginica
141 6.7 3.1 5.6 2.4 virginica
142 6.9 3.1 5.1 2.3 virginica
143 5.8 2.7 5.1 1.9 virginica
144 6.8 3.2 5.9 2.3 virginica
145 6.7 3.3 5.7 2.5 virginica
146 6.7 3.0 5.2 2.3 virginica
147 6.3 2.5 5.0 1.9 virginica
148 6.5 3.0 5.2 2.0 virginica
149 6.2 3.4 5.4 2.3 virginica
150 5.9 3.0 5.1 1.8 virginicaView(iris), agar tampilan dataset iris muncul di tab baru, seolah-olah telah melakukan double click di Environment. Perhatikan bahwa huruf “V” di perintah View harus huruf kapital.View(iris)Tentunya, data yang dihadapi oleh pengguna R pada umumnya tidak akan built-in, tetapi misalnya akan berupa file Excel (.xlsx) ataupun format .csv, sehingga harus di-import terlebih dahulu.
Untuk belajar cara import data, kebetulan dataset iris juga tersedia dalam format .csv dan juga .xlsx yang bisa kalian unduh:
Baik format .csv maupun format .xlsx menyimpan data yang bersifat “tabular”, atau berbentuk tabel. Bedanya, format .xlsx atau Excel bisa menyimpan hal lainnya seperti gambar grafik/visualisasi, juga tiap sel/data bisa diberi warna, dijadikan bold, dan sebagainya. Sedangkan, format CSV benar-benar hanya menyimpan data tabel saja.
“CSV” itu sendiri adalah singkatan dari comma-separated values. Kalau ada waktu, kalian bisa iseng mencoba membuka file .csv menggunakan aplikasi teks seperti Notepad (di Windows) atau TextEdit (di macOS). Kalian bisa melihat tiap nilai dipisahkan dengan koma, semikolon, atau tanda serupa, yang disebut delimeter.
Kebetulan, fitur import di R tidak langsung aktif, sehingga perlu diaktifkan terlebih dahulu, dan bahkan perlu diinstal sebelum diaktifkan.
Fitur import .csv, yang bernama read.csv, tersedia dari package atau library (yaitu sekumpulan fitur) yang bernama “readr”. Kode berikut menginstal package readr terlebih dahulu, kemudian mengaktifkannya:
install.packages("readr")library(readr)Sedangkan, fitur import .xlsx bernama read_excel dan berasal dari package readxl, yang juga perlu diinstal dan diaktifkan sebagai berikut:
install.packages("readxl")library(readxl)Ada baiknya, file .csv dan/atau file .xlsx yang ingin di-import diletakkan di folder yang sama dengan file .R yang sedang kalian gunakan. Kemudian, di tampilan RStudio bagian pojok kanan bawah, tepatnya di tab “Files”, kalian bisa mencari letak file-file tersebut. Setelah menemukannya, kalian tinggal memberi tahu RStudio bahwa file-file yang ingin kalian gunakan ada di situ, yaitu dengan menekan More > Set As Working Directory (masih di tab Files).
Dengan demikian, untuk meng-import Iris.csv, kalian tinggal mengetik
df1 <- read.csv("Iris.csv")dan untuk meng-import Iris.xlsx, kalian tinggal mengetik
df2 <- read_excel("Iris.xlsx")Beberapa catatan tentang kode di atas:
Isi dari fungsi read.csv ataupun read_excel, yang saat ini diisi string "Iris.csv" dan "Iris.xlsx", sebenarnya meminta path, yaitu semacam “alamat” yang dikenal oleh komputer untuk mencari letak dari file yang diinginkan. Apabila file berada di folder yang sama, cukup namanya saja yang diketik.
Alternatif dari More > Set As Working Directory adalah dengan malah menekan More > Copy Folder Path to Clipboard, untuk memperoleh string yang kemudian bisa kalian paste ke dalam perinah read.csv ataupun read_excel.
Ketika berurusan dengan path, jangan lupa ubah tiap backslash atau \ menjadi salah satu di antara dua pilihan berikut (sama saja):
garis miring biasa: /
ditulis dua kali: \\
Nama df1 dan df2 itu sebenarnya nama variabel, sehingga terserah kalian, tidak harus df1 ataupun df2.
“df” adalah singkatan dari data frame. Singkat cerita, data frame adalah tabel, yang bisa memiliki sejumlah kolom (terkadang disebut “fitur”) dan sejumlah baris.
Sampai sini, kita sudah memiliki tiga data frame, yaitu iris (built-in), df1 (dari .csv), dan df2 (dari .xlsx). Semuanya sama saja. Untuk eksplorasi lebih lanjut, mungkin kita gunakan nama df1 saja ya. Nanti kalau kalian ada data lain yang ingin dieksplorasi, kalian bisa mengganti path di kode import di atas.
Mari kita lihat lagi datanya:
View(df1)Kita bisa gunakan fungsi ls untuk melihat nama-nama kolom, dan fungsi dim untuk melihat ukuran/dimensi tabel (sekian baris dikali sekian kolom):
ls(df1)[1] "Petal.Length" "Petal.Width" "Sepal.Length" "Sepal.Width" "Species" dim(df1)[1] 150 5Kita bisa sekilas melihat data frame tersebut dengan
str(df1)'data.frame': 150 obs. of 5 variables:
$ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
$ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
$ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
$ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
$ Species : chr "setosa" "setosa" "setosa" "setosa" ...Untuk memilih kolom tertentu, gunakan simbol dolar atau $ seperti berikut:
nama_data_frame$nama_kolomMisalnya, untuk memanggil kolom Sepal.Length saja,
df1$Sepal.Length [1] 5.1 4.9 4.7 4.6 5.0 5.4 4.6 5.0 4.4 4.9 5.4 4.8 4.8 4.3 5.8 5.7 5.4 5.1
[19] 5.7 5.1 5.4 5.1 4.6 5.1 4.8 5.0 5.0 5.2 5.2 4.7 4.8 5.4 5.2 5.5 4.9 5.0
[37] 5.5 4.9 4.4 5.1 5.0 4.5 4.4 5.0 5.1 4.8 5.1 4.6 5.3 5.0 7.0 6.4 6.9 5.5
[55] 6.5 5.7 6.3 4.9 6.6 5.2 5.0 5.9 6.0 6.1 5.6 6.7 5.6 5.8 6.2 5.6 5.9 6.1
[73] 6.3 6.1 6.4 6.6 6.8 6.7 6.0 5.7 5.5 5.5 5.8 6.0 5.4 6.0 6.7 6.3 5.6 5.5
[91] 5.5 6.1 5.8 5.0 5.6 5.7 5.7 6.2 5.1 5.7 6.3 5.8 7.1 6.3 6.5 7.6 4.9 7.3
[109] 6.7 7.2 6.5 6.4 6.8 5.7 5.8 6.4 6.5 7.7 7.7 6.0 6.9 5.6 7.7 6.3 6.7 7.2
[127] 6.2 6.1 6.4 7.2 7.4 7.9 6.4 6.3 6.1 7.7 6.3 6.4 6.0 6.9 6.7 6.9 5.8 6.8
[145] 6.7 6.7 6.3 6.5 6.2 5.9Ringkasan data, meliputi statistik deskriptif seperti minimum, maksimum, dan rata-rata, bisa diperoleh dengan
summary(df1) Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
Median :5.800 Median :3.000 Median :4.350 Median :1.300
Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
Species
Length:150
Class :character
Mode :character
Apabila kalian spesifik memerlukan nilai tertentu, tiap statistik deskriptif ada perintahnya sendiri, yang bisa diterapkan untuk tiap kolom.
Sebagai contoh, untuk kolom Sepal.Length, berikut ukuran pemusatan data, misalnya median (nilai tengah) dan mean (rata-rata):
median(df1$Sepal.Length) # median (nilai tengah)[1] 5.8mean(df1$Sepal.Length) # rata-rata[1] 5.843333Untuk nilai modus (yang juga bisa dianggap ukuran pemusatan data), gunakan fungsi Mode dari package DescTools, yang tentunya perlu diinstal terlebih dahulu kalau belum, lalu diaktifkan (perhatikan huruf kapital):
install.packages("DescTools") # instal kalau belumlibrary(DescTools) # aktifkanMode(df1$Sepal.Length)[1] 5
attr(,"freq")
[1] 10Artinya, nilai yang paling sering muncul adalah 5, dengan frekuensi sebanyak 10 kali.
Kemudian, berikut ukuran keragaman data (juga disebut persebaran data):
var(df1$Sepal.Length) # variansi[1] 0.6856935sd(df1$Sepal.Length) # standard deviation[1] 0.8280661Berikut ukuran rentang data:
min(df1$Sepal.Length) # minimum[1] 4.3max(df1$Sepal.Length) # maksimum[1] 7.9range(df1$Sepal.Length) # rentang: batas bawah, batas atas[1] 4.3 7.9Beberapa ukuran lainnya:
length(df1$Sepal.Length) # banyaknya baris/data[1] 150sum(df1$Sepal.Length) # sumasi/jumlah seluruh data[1] 876.5Tentu, ukuran-ukuran tersebut berupa nilai yang nantinya bisa disimpan ataupun digunakan untuk perhitungan lain. Misalnya, ada yang namanya standard error:
std_err <- sd(df1$Sepal.Length) / sqrt(length(df1$Sepal.Length))Selain itu, ada juga fungsi untuk memperoleh data secara terurut, yaitu sort
sort(df1$Sepal.Length) [1] 4.3 4.4 4.4 4.4 4.5 4.6 4.6 4.6 4.6 4.7 4.7 4.8 4.8 4.8 4.8 4.8 4.9 4.9
[19] 4.9 4.9 4.9 4.9 5.0 5.0 5.0 5.0 5.0 5.0 5.0 5.0 5.0 5.0 5.1 5.1 5.1 5.1
[37] 5.1 5.1 5.1 5.1 5.1 5.2 5.2 5.2 5.2 5.3 5.4 5.4 5.4 5.4 5.4 5.4 5.5 5.5
[55] 5.5 5.5 5.5 5.5 5.5 5.6 5.6 5.6 5.6 5.6 5.6 5.7 5.7 5.7 5.7 5.7 5.7 5.7
[73] 5.7 5.8 5.8 5.8 5.8 5.8 5.8 5.8 5.9 5.9 5.9 6.0 6.0 6.0 6.0 6.0 6.0 6.1
[91] 6.1 6.1 6.1 6.1 6.1 6.2 6.2 6.2 6.2 6.3 6.3 6.3 6.3 6.3 6.3 6.3 6.3 6.3
[109] 6.4 6.4 6.4 6.4 6.4 6.4 6.4 6.5 6.5 6.5 6.5 6.5 6.6 6.6 6.7 6.7 6.7 6.7
[127] 6.7 6.7 6.7 6.7 6.8 6.8 6.8 6.9 6.9 6.9 6.9 7.0 7.1 7.2 7.2 7.2 7.3 7.4
[145] 7.6 7.7 7.7 7.7 7.7 7.9Selain statistik deskriptif, kita juga bisa menerapkan manipulasi sederhana pada data. Sebelumnya, kita telah menggunakan simbol dolar $ untuk melakukan subsetting, lebih tepatnya memilih kolom tertentu.
Fitur subsetting ini sebenarnya ada fungsinya sendiri, yang tidak hanya bisa memilih kolom tertentu, tetapi juga bisa memilih semua baris yang memenuhi kriteria tertentu pada kolom.
Contohnya, untuk memilih semua baris dengan spesies tertentu:
subset(df1, Species == "versicolor") Sepal.Length Sepal.Width Petal.Length Petal.Width Species
51 7.0 3.2 4.7 1.4 versicolor
52 6.4 3.2 4.5 1.5 versicolor
53 6.9 3.1 4.9 1.5 versicolor
54 5.5 2.3 4.0 1.3 versicolor
55 6.5 2.8 4.6 1.5 versicolor
56 5.7 2.8 4.5 1.3 versicolor
57 6.3 3.3 4.7 1.6 versicolor
58 4.9 2.4 3.3 1.0 versicolor
59 6.6 2.9 4.6 1.3 versicolor
60 5.2 2.7 3.9 1.4 versicolor
61 5.0 2.0 3.5 1.0 versicolor
62 5.9 3.0 4.2 1.5 versicolor
63 6.0 2.2 4.0 1.0 versicolor
64 6.1 2.9 4.7 1.4 versicolor
65 5.6 2.9 3.6 1.3 versicolor
66 6.7 3.1 4.4 1.4 versicolor
67 5.6 3.0 4.5 1.5 versicolor
68 5.8 2.7 4.1 1.0 versicolor
69 6.2 2.2 4.5 1.5 versicolor
70 5.6 2.5 3.9 1.1 versicolor
71 5.9 3.2 4.8 1.8 versicolor
72 6.1 2.8 4.0 1.3 versicolor
73 6.3 2.5 4.9 1.5 versicolor
74 6.1 2.8 4.7 1.2 versicolor
75 6.4 2.9 4.3 1.3 versicolor
76 6.6 3.0 4.4 1.4 versicolor
77 6.8 2.8 4.8 1.4 versicolor
78 6.7 3.0 5.0 1.7 versicolor
79 6.0 2.9 4.5 1.5 versicolor
80 5.7 2.6 3.5 1.0 versicolor
81 5.5 2.4 3.8 1.1 versicolor
82 5.5 2.4 3.7 1.0 versicolor
83 5.8 2.7 3.9 1.2 versicolor
84 6.0 2.7 5.1 1.6 versicolor
85 5.4 3.0 4.5 1.5 versicolor
86 6.0 3.4 4.5 1.6 versicolor
87 6.7 3.1 4.7 1.5 versicolor
88 6.3 2.3 4.4 1.3 versicolor
89 5.6 3.0 4.1 1.3 versicolor
90 5.5 2.5 4.0 1.3 versicolor
91 5.5 2.6 4.4 1.2 versicolor
92 6.1 3.0 4.6 1.4 versicolor
93 5.8 2.6 4.0 1.2 versicolor
94 5.0 2.3 3.3 1.0 versicolor
95 5.6 2.7 4.2 1.3 versicolor
96 5.7 3.0 4.2 1.2 versicolor
97 5.7 2.9 4.2 1.3 versicolor
98 6.2 2.9 4.3 1.3 versicolor
99 5.1 2.5 3.0 1.1 versicolor
100 5.7 2.8 4.1 1.3 versicolorTerlihat bahwa spesies “versicolor” terdata di baris ke-51 hingga baris ke-100.
Bisa juga, memilih semua baris dengan Sepal.Length yang cukup besar:
subset(df1, Sepal.Length >= 6) Sepal.Length Sepal.Width Petal.Length Petal.Width Species
51 7.0 3.2 4.7 1.4 versicolor
52 6.4 3.2 4.5 1.5 versicolor
53 6.9 3.1 4.9 1.5 versicolor
55 6.5 2.8 4.6 1.5 versicolor
57 6.3 3.3 4.7 1.6 versicolor
59 6.6 2.9 4.6 1.3 versicolor
63 6.0 2.2 4.0 1.0 versicolor
64 6.1 2.9 4.7 1.4 versicolor
66 6.7 3.1 4.4 1.4 versicolor
69 6.2 2.2 4.5 1.5 versicolor
72 6.1 2.8 4.0 1.3 versicolor
73 6.3 2.5 4.9 1.5 versicolor
74 6.1 2.8 4.7 1.2 versicolor
75 6.4 2.9 4.3 1.3 versicolor
76 6.6 3.0 4.4 1.4 versicolor
77 6.8 2.8 4.8 1.4 versicolor
78 6.7 3.0 5.0 1.7 versicolor
79 6.0 2.9 4.5 1.5 versicolor
84 6.0 2.7 5.1 1.6 versicolor
86 6.0 3.4 4.5 1.6 versicolor
87 6.7 3.1 4.7 1.5 versicolor
88 6.3 2.3 4.4 1.3 versicolor
92 6.1 3.0 4.6 1.4 versicolor
98 6.2 2.9 4.3 1.3 versicolor
101 6.3 3.3 6.0 2.5 virginica
103 7.1 3.0 5.9 2.1 virginica
104 6.3 2.9 5.6 1.8 virginica
105 6.5 3.0 5.8 2.2 virginica
106 7.6 3.0 6.6 2.1 virginica
108 7.3 2.9 6.3 1.8 virginica
109 6.7 2.5 5.8 1.8 virginica
110 7.2 3.6 6.1 2.5 virginica
111 6.5 3.2 5.1 2.0 virginica
112 6.4 2.7 5.3 1.9 virginica
113 6.8 3.0 5.5 2.1 virginica
116 6.4 3.2 5.3 2.3 virginica
117 6.5 3.0 5.5 1.8 virginica
118 7.7 3.8 6.7 2.2 virginica
119 7.7 2.6 6.9 2.3 virginica
120 6.0 2.2 5.0 1.5 virginica
121 6.9 3.2 5.7 2.3 virginica
123 7.7 2.8 6.7 2.0 virginica
124 6.3 2.7 4.9 1.8 virginica
125 6.7 3.3 5.7 2.1 virginica
126 7.2 3.2 6.0 1.8 virginica
127 6.2 2.8 4.8 1.8 virginica
128 6.1 3.0 4.9 1.8 virginica
129 6.4 2.8 5.6 2.1 virginica
130 7.2 3.0 5.8 1.6 virginica
131 7.4 2.8 6.1 1.9 virginica
132 7.9 3.8 6.4 2.0 virginica
133 6.4 2.8 5.6 2.2 virginica
134 6.3 2.8 5.1 1.5 virginica
135 6.1 2.6 5.6 1.4 virginica
136 7.7 3.0 6.1 2.3 virginica
137 6.3 3.4 5.6 2.4 virginica
138 6.4 3.1 5.5 1.8 virginica
139 6.0 3.0 4.8 1.8 virginica
140 6.9 3.1 5.4 2.1 virginica
141 6.7 3.1 5.6 2.4 virginica
142 6.9 3.1 5.1 2.3 virginica
144 6.8 3.2 5.9 2.3 virginica
145 6.7 3.3 5.7 2.5 virginica
146 6.7 3.0 5.2 2.3 virginica
147 6.3 2.5 5.0 1.9 virginica
148 6.5 3.0 5.2 2.0 virginica
149 6.2 3.4 5.4 2.3 virginicaSelain subsetting, ada juga indexing. Kita bisa mengakses baris dan kolom tertentu pada tabel menggunakan kurung siku.
Misalnya, perhatikan data Sepal.Width:
df1$Sepal.Width [1] 3.5 3.0 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 3.7 3.4 3.0 3.0 4.0 4.4 3.9 3.5
[19] 3.8 3.8 3.4 3.7 3.6 3.3 3.4 3.0 3.4 3.5 3.4 3.2 3.1 3.4 4.1 4.2 3.1 3.2
[37] 3.5 3.6 3.0 3.4 3.5 2.3 3.2 3.5 3.8 3.0 3.8 3.2 3.7 3.3 3.2 3.2 3.1 2.3
[55] 2.8 2.8 3.3 2.4 2.9 2.7 2.0 3.0 2.2 2.9 2.9 3.1 3.0 2.7 2.2 2.5 3.2 2.8
[73] 2.5 2.8 2.9 3.0 2.8 3.0 2.9 2.6 2.4 2.4 2.7 2.7 3.0 3.4 3.1 2.3 3.0 2.5
[91] 2.6 3.0 2.6 2.3 2.7 3.0 2.9 2.9 2.5 2.8 3.3 2.7 3.0 2.9 3.0 3.0 2.5 2.9
[109] 2.5 3.6 3.2 2.7 3.0 2.5 2.8 3.2 3.0 3.8 2.6 2.2 3.2 2.8 2.8 2.7 3.3 3.2
[127] 2.8 3.0 2.8 3.0 2.8 3.8 2.8 2.8 2.6 3.0 3.4 3.1 3.0 3.1 3.1 3.1 2.7 3.2
[145] 3.3 3.0 2.5 3.0 3.4 3.0Kebetulan, Sepal.Width adalah kolom kedua pada tabel. Dari tabel df1, kita bisa memilih lima baris pertama dari kolom kedua, yaitu lima baris pertama dari Sepal.Width, seperti berikut:
df1[1:5, 2][1] 3.5 3.0 3.2 3.1 3.6Perhatikan bahwa bentuk data di atas sudah tidak seperti data frame yang berbentuk tabel rapi. Kita bisa tambahkan opsi drop = FALSE agar tetap seperti tabel:
df1[1:5, 2, drop = FALSE] Sepal.Width
1 3.5
2 3.0
3 3.2
4 3.1
5 3.6Ada juga fungsi which yang agak terbalik dari subsetting: mencari baris mana saja yang memenuhi kriteria tertentu. Misalnya, kita bisa memperoleh baris mana saja yang memiliki data spesies tertentu.
which(df1$Species == "versicolor") [1] 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69
[20] 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88
[39] 89 90 91 92 93 94 95 96 97 98 99 100Gunanya? Kita bisa gabungkan ini dengan indexing:
index_versicolor <- which(df1$Species == "versicolor")
df1[index_versicolor,] # entah kenapa, harus ada koma Sepal.Length Sepal.Width Petal.Length Petal.Width Species
51 7.0 3.2 4.7 1.4 versicolor
52 6.4 3.2 4.5 1.5 versicolor
53 6.9 3.1 4.9 1.5 versicolor
54 5.5 2.3 4.0 1.3 versicolor
55 6.5 2.8 4.6 1.5 versicolor
56 5.7 2.8 4.5 1.3 versicolor
57 6.3 3.3 4.7 1.6 versicolor
58 4.9 2.4 3.3 1.0 versicolor
59 6.6 2.9 4.6 1.3 versicolor
60 5.2 2.7 3.9 1.4 versicolor
61 5.0 2.0 3.5 1.0 versicolor
62 5.9 3.0 4.2 1.5 versicolor
63 6.0 2.2 4.0 1.0 versicolor
64 6.1 2.9 4.7 1.4 versicolor
65 5.6 2.9 3.6 1.3 versicolor
66 6.7 3.1 4.4 1.4 versicolor
67 5.6 3.0 4.5 1.5 versicolor
68 5.8 2.7 4.1 1.0 versicolor
69 6.2 2.2 4.5 1.5 versicolor
70 5.6 2.5 3.9 1.1 versicolor
71 5.9 3.2 4.8 1.8 versicolor
72 6.1 2.8 4.0 1.3 versicolor
73 6.3 2.5 4.9 1.5 versicolor
74 6.1 2.8 4.7 1.2 versicolor
75 6.4 2.9 4.3 1.3 versicolor
76 6.6 3.0 4.4 1.4 versicolor
77 6.8 2.8 4.8 1.4 versicolor
78 6.7 3.0 5.0 1.7 versicolor
79 6.0 2.9 4.5 1.5 versicolor
80 5.7 2.6 3.5 1.0 versicolor
81 5.5 2.4 3.8 1.1 versicolor
82 5.5 2.4 3.7 1.0 versicolor
83 5.8 2.7 3.9 1.2 versicolor
84 6.0 2.7 5.1 1.6 versicolor
85 5.4 3.0 4.5 1.5 versicolor
86 6.0 3.4 4.5 1.6 versicolor
87 6.7 3.1 4.7 1.5 versicolor
88 6.3 2.3 4.4 1.3 versicolor
89 5.6 3.0 4.1 1.3 versicolor
90 5.5 2.5 4.0 1.3 versicolor
91 5.5 2.6 4.4 1.2 versicolor
92 6.1 3.0 4.6 1.4 versicolor
93 5.8 2.6 4.0 1.2 versicolor
94 5.0 2.3 3.3 1.0 versicolor
95 5.6 2.7 4.2 1.3 versicolor
96 5.7 3.0 4.2 1.2 versicolor
97 5.7 2.9 4.2 1.3 versicolor
98 6.2 2.9 4.3 1.3 versicolor
99 5.1 2.5 3.0 1.1 versicolor
100 5.7 2.8 4.1 1.3 versicolorSebenarnya, ada alternatif dari fungsi subset, yaitu fungsi filter dari package dplyr. Mari instal kalau belum, lalu aktifkan:
install.packages("dplyr")library(dplyr)
Attaching package: 'dplyr'The following objects are masked from 'package:stats':
filter, lagThe following objects are masked from 'package:base':
intersect, setdiff, setequal, unionKita bisa gunakan sebagaimana menggunakan fungsi subset tadi:
filter(df1, Species == "versicolor") Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 7.0 3.2 4.7 1.4 versicolor
2 6.4 3.2 4.5 1.5 versicolor
3 6.9 3.1 4.9 1.5 versicolor
4 5.5 2.3 4.0 1.3 versicolor
5 6.5 2.8 4.6 1.5 versicolor
6 5.7 2.8 4.5 1.3 versicolor
7 6.3 3.3 4.7 1.6 versicolor
8 4.9 2.4 3.3 1.0 versicolor
9 6.6 2.9 4.6 1.3 versicolor
10 5.2 2.7 3.9 1.4 versicolor
11 5.0 2.0 3.5 1.0 versicolor
12 5.9 3.0 4.2 1.5 versicolor
13 6.0 2.2 4.0 1.0 versicolor
14 6.1 2.9 4.7 1.4 versicolor
15 5.6 2.9 3.6 1.3 versicolor
16 6.7 3.1 4.4 1.4 versicolor
17 5.6 3.0 4.5 1.5 versicolor
18 5.8 2.7 4.1 1.0 versicolor
19 6.2 2.2 4.5 1.5 versicolor
20 5.6 2.5 3.9 1.1 versicolor
21 5.9 3.2 4.8 1.8 versicolor
22 6.1 2.8 4.0 1.3 versicolor
23 6.3 2.5 4.9 1.5 versicolor
24 6.1 2.8 4.7 1.2 versicolor
25 6.4 2.9 4.3 1.3 versicolor
26 6.6 3.0 4.4 1.4 versicolor
27 6.8 2.8 4.8 1.4 versicolor
28 6.7 3.0 5.0 1.7 versicolor
29 6.0 2.9 4.5 1.5 versicolor
30 5.7 2.6 3.5 1.0 versicolor
31 5.5 2.4 3.8 1.1 versicolor
32 5.5 2.4 3.7 1.0 versicolor
33 5.8 2.7 3.9 1.2 versicolor
34 6.0 2.7 5.1 1.6 versicolor
35 5.4 3.0 4.5 1.5 versicolor
36 6.0 3.4 4.5 1.6 versicolor
37 6.7 3.1 4.7 1.5 versicolor
38 6.3 2.3 4.4 1.3 versicolor
39 5.6 3.0 4.1 1.3 versicolor
40 5.5 2.5 4.0 1.3 versicolor
41 5.5 2.6 4.4 1.2 versicolor
42 6.1 3.0 4.6 1.4 versicolor
43 5.8 2.6 4.0 1.2 versicolor
44 5.0 2.3 3.3 1.0 versicolor
45 5.6 2.7 4.2 1.3 versicolor
46 5.7 3.0 4.2 1.2 versicolor
47 5.7 2.9 4.2 1.3 versicolor
48 6.2 2.9 4.3 1.3 versicolor
49 5.1 2.5 3.0 1.1 versicolor
50 5.7 2.8 4.1 1.3 versicolorfilter(df1, Sepal.Length >= 6) Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 7.0 3.2 4.7 1.4 versicolor
2 6.4 3.2 4.5 1.5 versicolor
3 6.9 3.1 4.9 1.5 versicolor
4 6.5 2.8 4.6 1.5 versicolor
5 6.3 3.3 4.7 1.6 versicolor
6 6.6 2.9 4.6 1.3 versicolor
7 6.0 2.2 4.0 1.0 versicolor
8 6.1 2.9 4.7 1.4 versicolor
9 6.7 3.1 4.4 1.4 versicolor
10 6.2 2.2 4.5 1.5 versicolor
11 6.1 2.8 4.0 1.3 versicolor
12 6.3 2.5 4.9 1.5 versicolor
13 6.1 2.8 4.7 1.2 versicolor
14 6.4 2.9 4.3 1.3 versicolor
15 6.6 3.0 4.4 1.4 versicolor
16 6.8 2.8 4.8 1.4 versicolor
17 6.7 3.0 5.0 1.7 versicolor
18 6.0 2.9 4.5 1.5 versicolor
19 6.0 2.7 5.1 1.6 versicolor
20 6.0 3.4 4.5 1.6 versicolor
21 6.7 3.1 4.7 1.5 versicolor
22 6.3 2.3 4.4 1.3 versicolor
23 6.1 3.0 4.6 1.4 versicolor
24 6.2 2.9 4.3 1.3 versicolor
25 6.3 3.3 6.0 2.5 virginica
26 7.1 3.0 5.9 2.1 virginica
27 6.3 2.9 5.6 1.8 virginica
28 6.5 3.0 5.8 2.2 virginica
29 7.6 3.0 6.6 2.1 virginica
30 7.3 2.9 6.3 1.8 virginica
31 6.7 2.5 5.8 1.8 virginica
32 7.2 3.6 6.1 2.5 virginica
33 6.5 3.2 5.1 2.0 virginica
34 6.4 2.7 5.3 1.9 virginica
35 6.8 3.0 5.5 2.1 virginica
36 6.4 3.2 5.3 2.3 virginica
37 6.5 3.0 5.5 1.8 virginica
38 7.7 3.8 6.7 2.2 virginica
39 7.7 2.6 6.9 2.3 virginica
40 6.0 2.2 5.0 1.5 virginica
41 6.9 3.2 5.7 2.3 virginica
42 7.7 2.8 6.7 2.0 virginica
43 6.3 2.7 4.9 1.8 virginica
44 6.7 3.3 5.7 2.1 virginica
45 7.2 3.2 6.0 1.8 virginica
46 6.2 2.8 4.8 1.8 virginica
47 6.1 3.0 4.9 1.8 virginica
48 6.4 2.8 5.6 2.1 virginica
49 7.2 3.0 5.8 1.6 virginica
50 7.4 2.8 6.1 1.9 virginica
51 7.9 3.8 6.4 2.0 virginica
52 6.4 2.8 5.6 2.2 virginica
53 6.3 2.8 5.1 1.5 virginica
54 6.1 2.6 5.6 1.4 virginica
55 7.7 3.0 6.1 2.3 virginica
56 6.3 3.4 5.6 2.4 virginica
57 6.4 3.1 5.5 1.8 virginica
58 6.0 3.0 4.8 1.8 virginica
59 6.9 3.1 5.4 2.1 virginica
60 6.7 3.1 5.6 2.4 virginica
61 6.9 3.1 5.1 2.3 virginica
62 6.8 3.2 5.9 2.3 virginica
63 6.7 3.3 5.7 2.5 virginica
64 6.7 3.0 5.2 2.3 virginica
65 6.3 2.5 5.0 1.9 virginica
66 6.5 3.0 5.2 2.0 virginica
67 6.2 3.4 5.4 2.3 virginicaBedanya dengan fungsi subset? Selain namanya lebih jelas, fungsi filter ini cenderung lebih cepat untuk data yang besar, misalnya puluhan ribu baris.
Terkadang, data lebih enak dilihat ketika divisualisasikan. Sebagaimana yang kalian pelajari di kelas kuliah, ada berbagai macam visualisasi untuk berbagai macam data.
Kita akan membahas lebih lanjut tentang visualisasi di pertemuan selanjutnya. Kali ini, kita akan mencoba beberapa visualisasi sederhana, yaitu visualisasi frekuensi, yang masing-masing melibatkan satu variabel saja. Tujuannya adalah agar bisa menggambarkan (sehingga lebih memahami) bagaimana persebaran nilai-nilai untuk suatu variabel, yaitu persebaran frekuensinya.
Sebelum bisa membuat visualisasi, kita perlu mempersiapkan datanya. Misalnya, kita ingin mengetahui persebaran spesies di data df1. Data yang perlu kita persiapkan adalah tabel frekuensi (frequency table), yang mendata banyaknya kemunculan tiap nilai. Dalam hal ini, tabel frekuensi untuk spesies akan mendata banyaknya baris pada data yang ada untuk tiap spesies.
Cara membuatnya adalah sebagai berikut. Kita terapkan fungsi table pada df1$Species untuk menghasilkan data tabel frekuensi, kemudian menerapkan fungsi data.frame untuk memperoleh hasil tabel yang rapi (berbentuk data frame). Hasil dari semua itu kita simpan ke dalam suatu variabel, misal freq_species, yang akan menyimpan data frame tabel frekuensi tersebut.
freq_species <- data.frame(table(df1$Species, dnn="Species"))
freq_species Species Freq
1 setosa 50
2 versicolor 50
3 virginica 50View(freq_species)Catatan: dnn adalah opsi nama kolom untuk variabel yang ingin dihitung frekuensinya. Apabila tidak diberikan, namanya akan “Var1”.
Ternyata hasilnya tidak begitu menarik, ketiga spesies tersebar rata. Tidak masalah, kita bisa mencoba mem-filter data dengan kriteria tertentu, barulah membuat tabel frekuensinya.
Sebagai contoh, kita penasaran bagaimana persebaran spesies ketika panjang sepal atau Sepal.Length cukup besar, minimal 5.5. Kita bisa filter terlebih dahulu dengan fungsi subset, dan menyimpan hasil saringannya (yang berupa data frame) ke dalam suatu variabel baru, misalnya df1_longsepal
df1_longsepal <- subset(df1, Sepal.Length >= 5.5)Barulah kita buat tabel frekuensinya:
freq_species_longsepal <- data.frame(table(df1_longsepal$Species,
dnn="Species"))
freq_species_longsepal Species Freq
1 setosa 5
2 versicolor 44
3 virginica 49Menarik! Panjang sepal untuk spesies tertentu cenderung lebih kecil daripada spesies lainnya.
Perhatikan bahwa Species di sini tergolong data kategorik, sehingga kita bisa mencoba membuat bar chart dan pie chart untuk menggambarkan kedua tabel frekuensi di atas.
Gunakan fungsi barplot
barplot(height = freq_species$Freq,
names.arg = freq_species$Species,
col = "violet",
main = "Persebaran Spesies (seluruh data)",
xlab = "Spesies", ylab = "Frekuensi",
width = 1, space = 2, density = 10,
font.axis = 2,
col.axis = "red",
cex.axis = 1)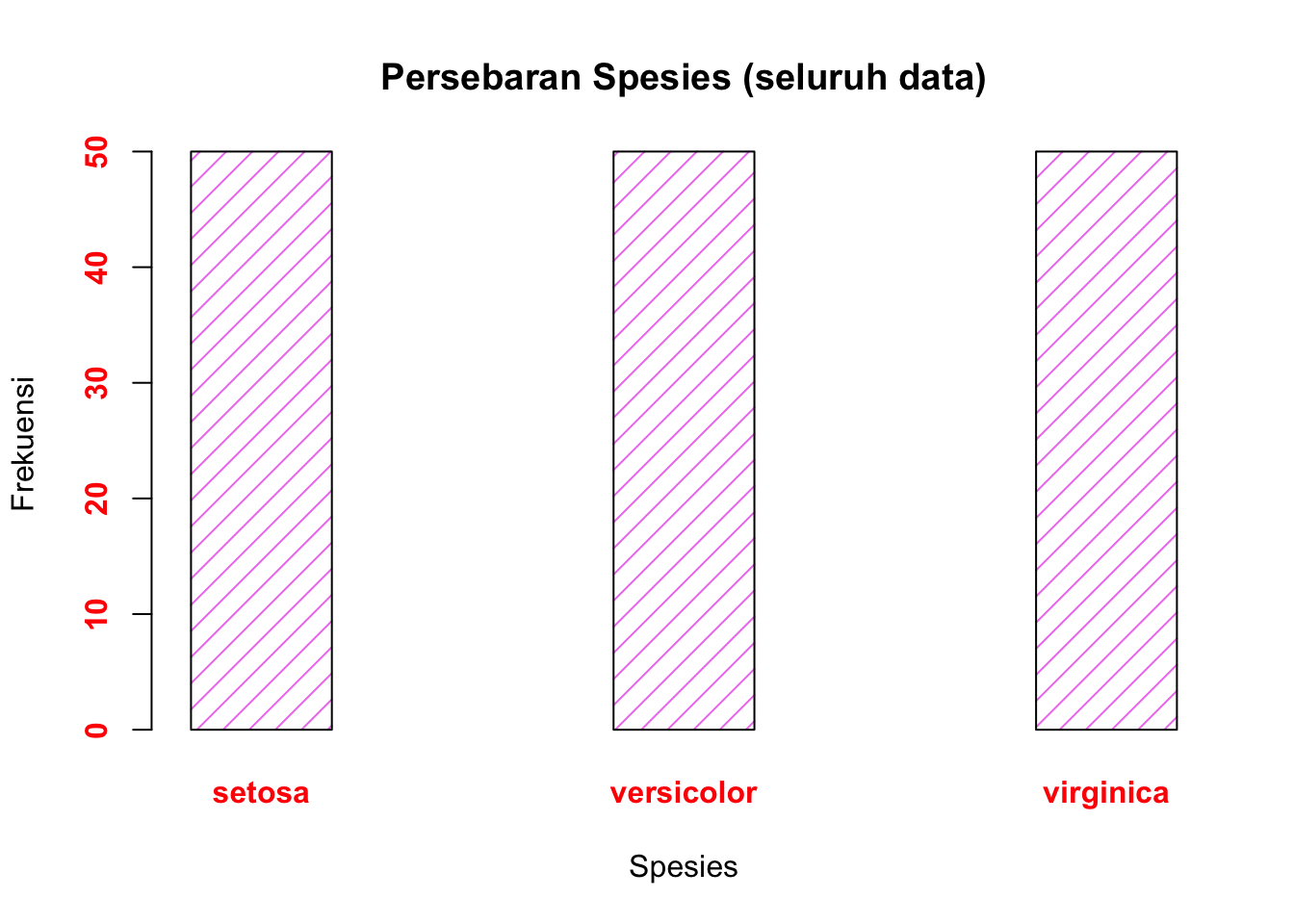
barplot(height = freq_species_longsepal$Freq,
names.arg = freq_species_longsepal$Species,
main = "Persebaran Spesies (untuk Sepal.Length >= 5.5)",
xlab = "Spesies",
ylab = "Frekuensi")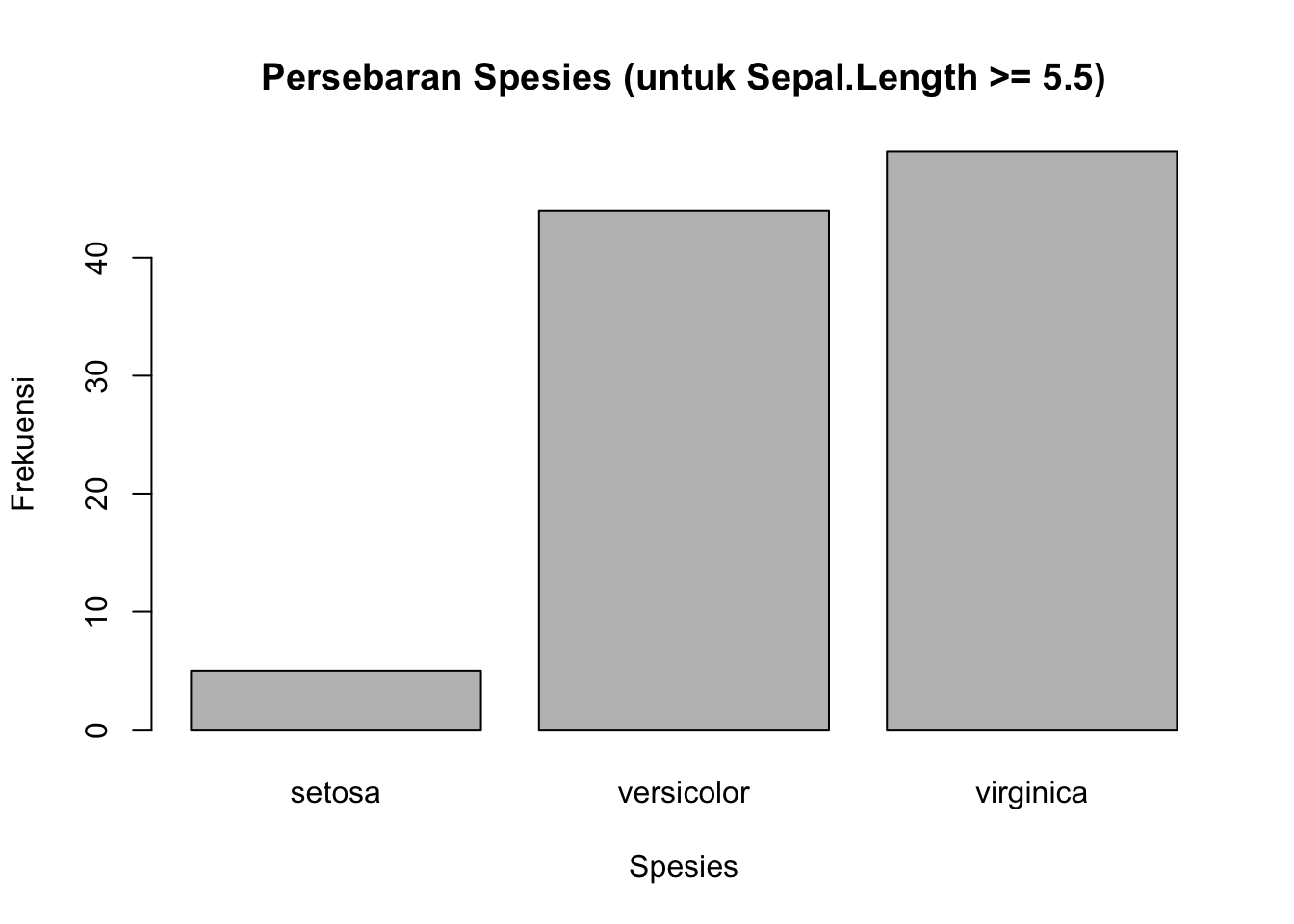
Gunakan fungsi pie
pie(freq_species$Freq,
labels = freq_species$Species,
main = "Persebaran Spesies (seluruh data)",
col = c("red", "green", "blue"))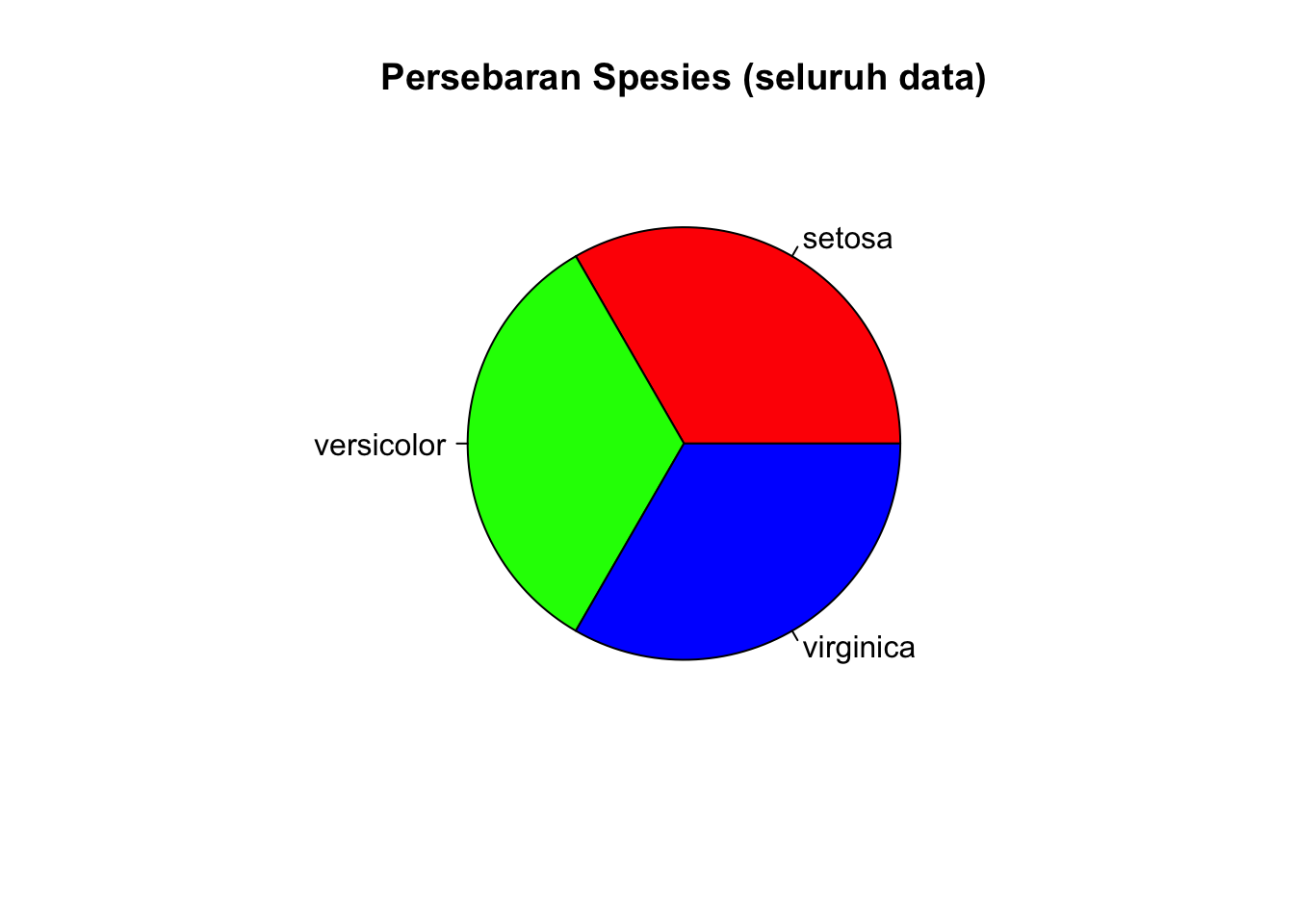
pie(freq_species_longsepal$Freq,
labels = freq_species_longsepal$Species,
main = "Persebaran Spesies (untuk Sepal.Length >= 5.5)")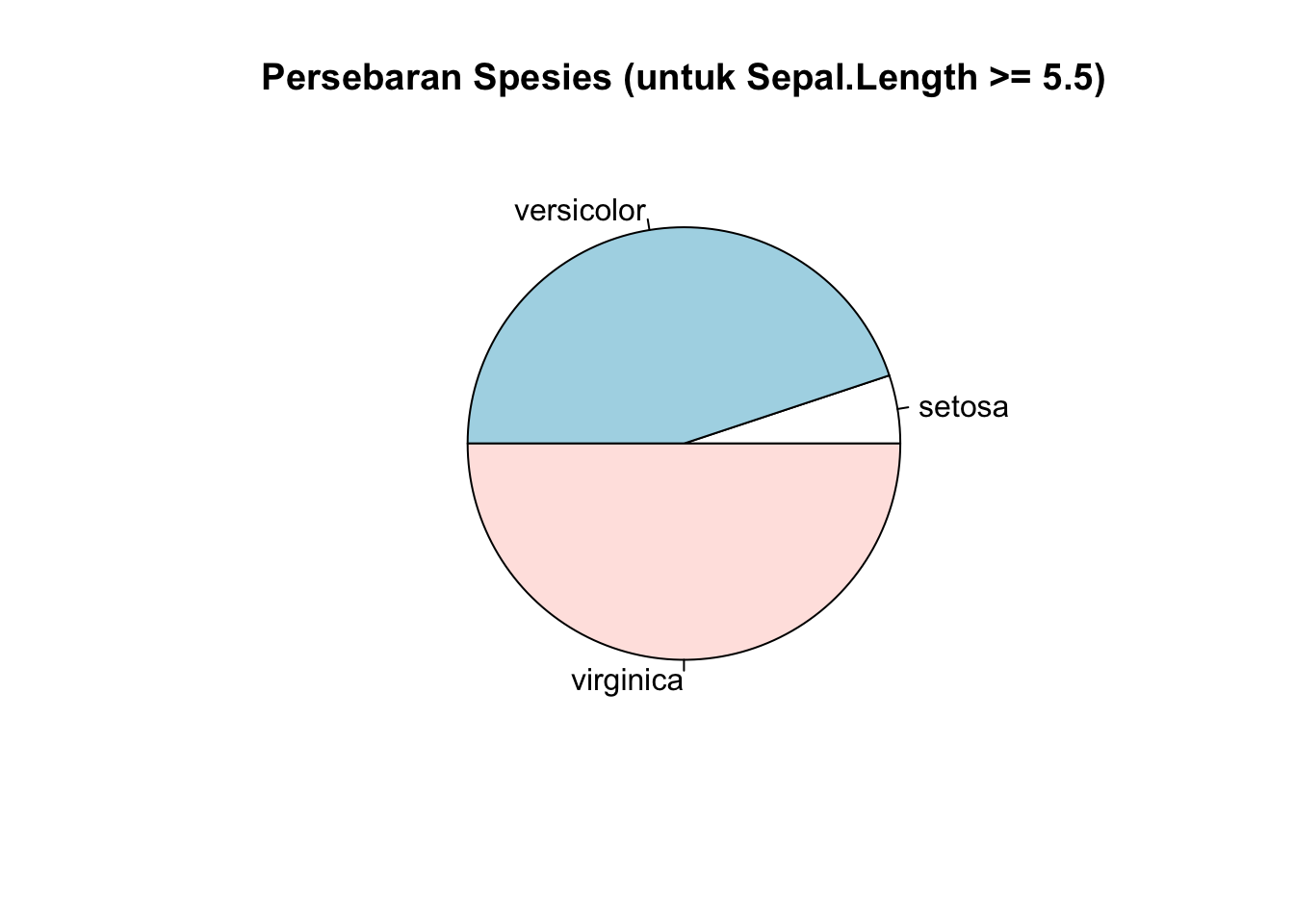
Sayangnya, variabel kategorik di dataset iris hanyalah Species, sedangkan variabel lainnya berupa data numerik.
Untuk data numerik, histogram cukup umum digunakan untuk menggambarkan persebaran datanya, yang terlebih dahulu dibagi-bagi menjadi sejumlah “kelas” atau “kelompok”.
Histogram seolah-olah seperti bar chart untuk data numerik yang harus dikelompokkan terlebih dahulu. Untungnya, R bisa otomatis melakukan pengelompokkan tersebut, sehingga kita tinggal pakai; tidak perlu membuat tabel frekuensi secara manual seperti untuk data kategorik.
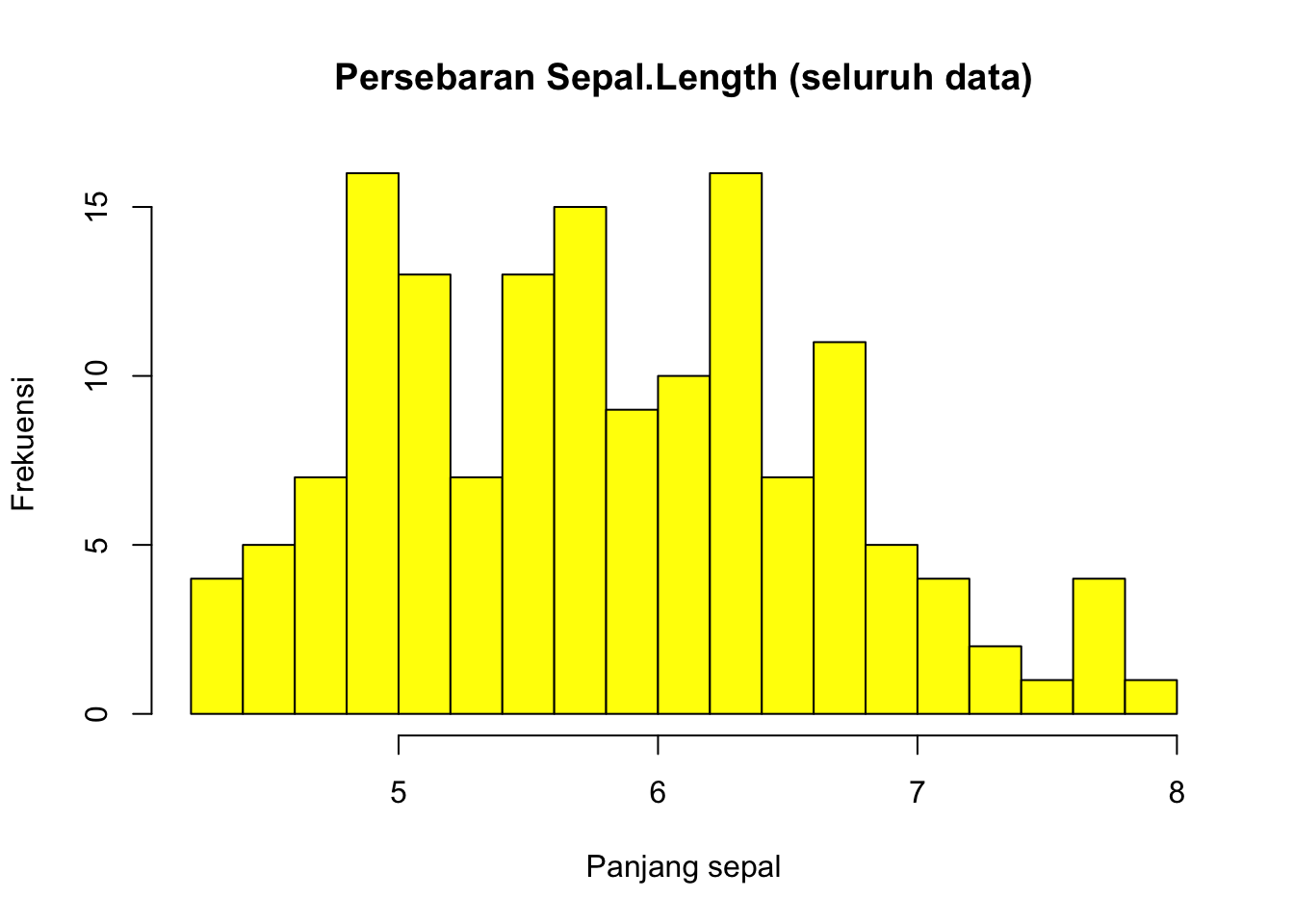
Fungsi yang digunakan adalah hist. Sebagai contoh, berikut gambaran persebaran Sepal.Length
hist(df1$Sepal.Length,
main = "Persebaran Sepal.Length (seluruh data)",
xlab = "Panjang sepal",
ylab = "Frekuensi",
col = "yellow")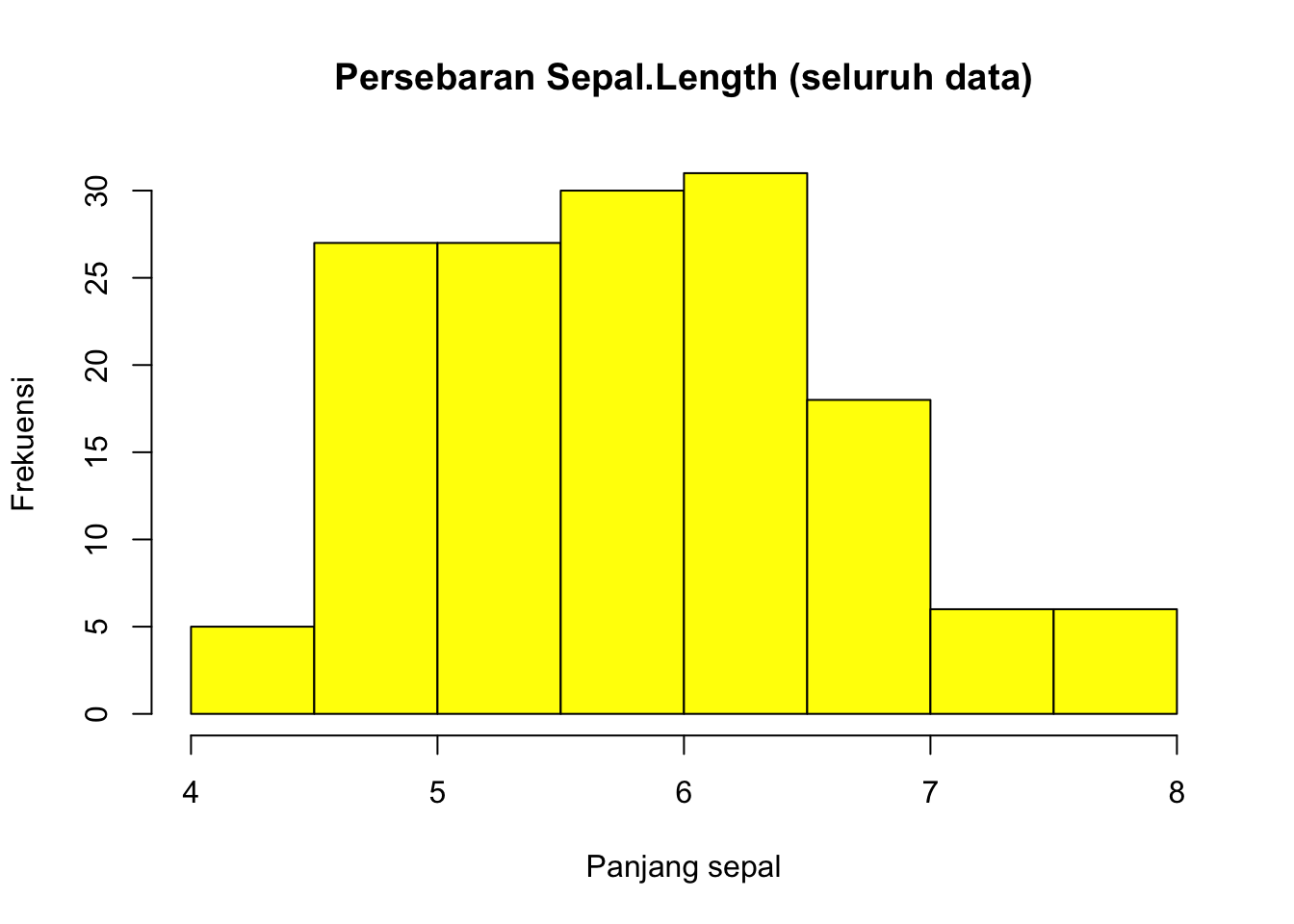
Kita bisa menentukan banyaknya kelompok yang kita inginkan, dengan opsi breaks
hist(df1$Sepal.Length,
main = "Persebaran Sepal.Length (seluruh data)",
xlab = "Panjang sepal",
ylab = "Frekuensi",
col = "yellow",
breaks = 20)