import pandas as pd
obj = pd.Series([4, 7, -5, 3])
objPertemuan 1 : Python for Data Analysis
Intro to Pandas
Offline di Departemen Matematika: sesi 1 di lab komputer D.311, sesi 2 di lab statistika D.406
Kembali ke EDA
Data Analysis Libraries
Library pada python adalah potongan kode yang reusable dan dapat kita akses dengan mengimpornya ke dalam program kita. Pada mata kuliah algoritma dan pemrograman yang telah kalian ambil di semester 1, telah diperkenalkan beberapa library yang dapat kalian import ke dalam script kalian seperti numpy, scipy, sympy, pandas, matplotlib dan lainnya.
Dalam bidang data analysis, library python yang umum digunakan adalah numpy dan pandas untuk pengolahan data tabular, matplotlib dan seaborn untuk visualisasi
Jika anda menggunakan jupyter notebook secara local pada perangkat anda, anda perlu menginstall 3 library tersebut untuk praktikum ini. Gunakan python package manager (pip) untuk menginstall library numpy, pandas, matplotlib dan seaborn dengan memanggil pip install <nama-library> di terminal. Jika anda menggunakan conda atau google colab, library-library ini sudah terinstall secara otomatis dan dapat kita import secara langsung.
Untuk mengecek apakah library yang diperlukan sudah terinstall, run blok kode di bawah ini.
# Untuk library lain, ubah `pandas` -> <nama-library>
import pandas
pandas.__version__Jika library sudah terinstall, maka output akan menunjukkan versi dari library yang terinstall.
TipKesepakatan Penamaan Library
Komunitas python memiliki kesepakatan penamaan untuk beberapa library untuk memudahkan pembacaan kode. Beberapa diantaranya yang kita gunakan adalah
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsStruktur Data Pandas (Series, DataFrame, Index Objects)
Pada dasarnya, pandas dibuat atas struktur data yang terdapat pada library NumPy yaitu Array. Array sendiri sudah pernah dibahas dalam mata kuliah algoritma dan pemrograman sehingga kita tidak akan mendalaminya pada praktikum ini.
Series
Series adalah suatu object yang menyerupai array 1 dimensi yang memiliki nilai dengan array index yang berkaitan dengan masing-masing nilai.
kolom kiri adalah index, kolom kanan adalah Values (nilai).
Untuk mengakses values saja :
obj.valuesUntuk mengakses index saja :
obj.indexPerbedaan Series dengan Array
Dengan Series kita bisa menggunakan index untuk mengakses value yang berkaitan dengan index tersebut.
obj[0]obj[1] = 2
obj[[0, 1, 3]]obj[0:2]Series dengan custom index
obj2 = pd.Series([0.25, 0.5, 0.75, 1.0], index=['d', 'b', 'a', 'c'])
obj2
WarningError warning
Perhatikan jumlah index harus sama dengan jumlah value yang ditetapkan.
obj2.indexobj2['b']obj2['d':'a']Untuk mengubah index suatu series bisa juga dengan mengubah nilai <series>.index
obj2.index = ['A', 'B', 'C', 'D']
obj2Series as specialized dictionary
Dictionary pada python adalah struktur data yang berisi pasangan key-value. Kita dapat melihat series sebagai pasangan key-value dengan index sebagai key. Bahkan kita bisa membuat suatu series dari sebuah dictionary.
data_dict = {
'Jakarta': 400,
'Bandung': 200,
'Bogor': 300,
'Depok': 500
}
data_dictdata_series = pd.Series(data_dict)
data_seriesJika kita ingin index dengan urutan tertentu, maka kita dapat memasukkan argumen index berupa list index sesuai dengan urutan yang kita inginkan.
kota = ['Surabaya', 'Bandung', 'Bogor', 'Jakarta']
data_series2 = pd.Series(data_dict, index=kota)
data_series2
Tip
Perhatikan bahwa jika kita memasukkan index yang tidak ada pada dictionary awal, index akan dimasukkan dengan nilai NaN (Not a Number)
Operasi Aritmatika
Series secara otomatis menyamakan index ketika melakukan operasi aritmatika.
data_series + data_series2 # Silahkan coba untuk operasi aritmatika lainnya
Tip
Perhatikan bahwa Depok dan Surabaya bernilai NaN. Hal ini dikarenakan kedua index tersebut tidak terdapat pada kedua series yang kita operasikan.
name attribute
Object series dan index pada pandas memiliki atribut name yaitu nama dari series/index tersebut.
data_series.name = 'populasi'
data_series.index.name = 'kota'
data_seriesDataFrame
DataFrame adalah struktur data 2 dimensi yang terdiri atas baris dan kolom (disebut juga tabel). Kita dapat melihat dataframe sebagai gabungan dari 2 atau lebih series.
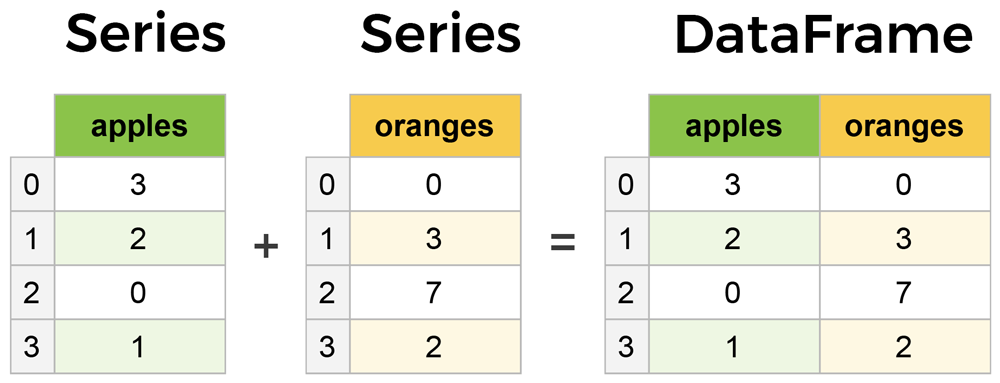
Karena memiliki 2 dimensi (baris dan kolom), DataFrame memiliki indeks untuk masing-masing baris dan kolom.
Ada banyak cara untuk membangun DataFrame, salah satu yang paling umum adalah membuat dictionary dengan
key : nama kolom
value : nilai-nilai dalam list atau NumPy Array dengan panjang yang sama untuk setiap kolom.
value : nilai-nilai dalam list atau NumPy Array dengan panjang yang sama untuk setiap kolom.
data = {'kota': ['Bogor', 'Bogor', 'Bogor', 'Depok', 'Depok', 'Depok'],
'tahun': [2000, 2001, 2002, 2001, 2002, 2003],
'populasi': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]}
df = pd.DataFrame(data) # `df` adalah singkatan yang umum digunakan oleh komunitas python dalam mendefinisikan suatu `dataframe`
dfpd.DataFrame() menerima argumen columns= yang dapat digunakan untuk menentukan urutan kolom dataframe.
df2 = pd.DataFrame(data, columns=['tahun', 'kota', 'populasi'])
df2
Tip
- menambahkan kolom baru yang tidak ada pada data akan menghasilkan kolom berisi nilai
NaN pd.DataFramejuga menerima argumenindex=untuk mengubah index seperti padapd.Series
df2 = pd.DataFrame(data, columns=['tahun', 'kota', 'populasi', 'luas_wilayah'],
index=['one', 'two', 'three', 'four', 'five', 'six'])
df2Importing datasets
Dalam mengolah suatu data, tidaklah mungkin kita harus menulis ulang seluruh data yang sudah tertulis dengan format tertentu (misalnya Spreadsheet/.xlsx, .csv, atau .dat) pastinya kita perlu suatu cara untuk mengimpor data yang memiliki berbagai format. Pandas memiliki beberapa function yang dapat kita gunakan untuk membaca data dengan berbagai format.
- .csv (comma separated values)
df = pd.read_csv('<path-to-csv>')- .xlsx (excel spreadsheet)
df = pd.read_excel('<path-to-xlsx>')- Others
Untuk tipe file lainnya, silahkan baca dokumentasi pandas di link berikut : Pandas IO Tools
DataFrame Attributes/Properties and Methods
Sejauh ini kita sudah berkenalan dengan 2 object pandas yaitu Series dan DataFrame. Dalam pemrograman python, sebuah object bisa memiliki suatu method, attribute/property, atau keduanya.
Untuk materi selanjutnya, kita akan menggunakan dataset pokemon sebagai contoh. Jalankan code block di bawah ini.
df = pd.read_csv('https://raw.githubusercontent.com/farhanage/dataset-for-study/main/pokemon_data.csv')head()
Memanggil method head akan mengembalikan beberapa baris pertama dari suatu dataframe.
df.head(3) # Membaca 3 baris pertamatail()
Memanggil method tail akan mengembalikan beberapa baris terakhir dari suatu dataframe.
df.tail(3) # Membaca 3 baris terakhir
Tip
Secara default, method head() dan tail() akan mengembalikan 5 baris pertama/terakhir jika tidak diberikan suatu argumen.
shape
Memanggil attribute shape akan memberikan kita jumlah baris dan kolom dari suatu dataframe.
df.shape # Mengembalikan (jumlah_baris, jumlah_kolom)columns
Memanggil attribute columns akan memberikan kita index object berisi semua nama kolom dari suatu dataframe.
df.columns # Mengembalikan index object berisi semua nama kolom dari suatu dataframeindex
Memanggil attribute columns akan memberikan kita index object berisi index baris suatu dataframe.
df.index # Mengembalikan index object berisi index suatu dataframePandas dataframe memiliki banyak sekali methods dan attributes/properties. Untuk mempelajari lebih lanjut mengenai dataframe pandas, dokumentasi library pandas bisa diakses pada link berikut : Pandas essential basic functionality
Index
Perhatikan pada atribut columns dan index yang telah dibahas sebelumnya, output kode adalah object index. Apa itu object index? Dalam library Pandas, object index digunakan sebagai object yang menyimpan label suatu object lainnya.
Contoh : dalam object DataFrame, index object digunakan untuk menyimpan label baris (df.index) dan kolom (df.columns).
obj = pd.Series(range(3), index=['a', 'b', 'c'])
obj.indexobj.index[1]obj.index[1:]
WarningError warning
Index object bersifat immutable, artinya nilai dari suatu index tidak dapat diubah.
obj.index[1] = 'd'Index object juga memiliki beberapa attribute dan methods. Beberapa diantaranya :

Basic Functionality
Indexing, Selection and Filtering
Indexing and Selection
Series indexing digunakan untuk mengambil value yang berkaitan dengan suatu index.
import numpy as np
obj = pd.Series(np.arange(4.), index=['a', 'b', 'c', 'd'])
objobj['b'] # Memanggil nilai dengan index `a`obj['a':'c'] # Memanggil nilai dengan index `a` hingga `c`
Important
Perhatikan, saat melakukan slicing dengan explicit index (misal, data['a':'c']), final index diikutsertakan dalam outputnya (inklusif), sementara ketika melakukan slicing dengan implicit index (misal, data[0:2]), final index tidak diikutsertakan dalam outputnya (tidak inklusif).
DataFrame indexing digunakan untuk mengambil 1 atau beberapa kolom dengan memanggil label/nama kolom yang bersesuaian.
df['Name']df[['Name']]
Important
df['<column-name>'] akan mengembalikan kolom yang bersesuaian dalam bentuk Series.df[['<column-name>']] akan mengembalikan kolom yang bersesuaian dalam bentuk dataframe.df[['Name','HP','Defense']]Kita bisa membuat suatu kolom baru dari kolom-kolom yang sudah ada. Misalkan kita buat suatu variabel bernama Total Attack yang berisi hasil penjumlahan variabel Attack dan Sp. Atk
df['Total Attack'] = df['Attack'] + df['Sp. Atk']
df[['Attack','Sp. Atk','Total Attack']]Untuk indexing baris suatu dataframe, gunakan index baris
df[:3] # Mengambil baris dengan index 0 - 2df[0:5:2] # Mengambil dengan index 0 sampai 4 dengan step 2Filtering
Untuk melakukan filtering pada suatu dataframe :
df[df['HP'] == 50] # Mengambil data pada dataframe df yang memiliki nilai kolom `HP` == 50df[df['HP'] > 50] # Mengambil data pada dataframe df yang memiliki nilai kolom `HP` > 50df[(df['HP'] > 100) & (df['Type 1'] == 'Fire')] # Mengambil data pada dataframe df yang memiliki nilai kolom `HP` > 100 dan `Type 1` == Firedf[(df['HP'] > 100) | (df['Type 1'] == 'Fire')] # Mengambil data pada dataframe df yang memiliki nilai kolom `HP` > 100 atau `Type 1` == FireUntuk filter yang lebih rumit, disarankan untuk mendefinisikan variabel condition agar kode mudah terbaca.
Contoh : Filter (HP >= 150) dan ((Type 1 == Water) atau (Legendary == True))
condition = (df['HP'] >= 150) & ((df['Type 1'] == 'Water') | (df['Legendary'] == True))
df[condition]Case Study (Toko Baju Unikloh)
Link Dataset : Data Penjualan Toko Baju Unikloh
Sebuah toko baju unikloh membutuhkan jasa seorang analis untuk menganalisis data penjualan baju yang mereka miliki. Sebelum itu, Pak Joko selaku pemilik toko ingin tahu beberapa hal mengenai data yang dia miliki. Berikut yang beliau minta :
- Ada berapa banyak data penjualan kita?
Hint
# Jumlah data penjualan bisa kita akses dengan melihat `jumlah baris` suatu dataframe.Answer
sales_df.shape- Beliau minta 10 data pertama untuk melihat gambaran umum nilai masing-masing variabel.
Hint
# Gunakan method `.head()`Answer
sales_df.head(10)- Beliau mau fokus melihat kolom
price_per_unitdanquantitysaja.
Hint
# Untuk mengambil beberapa kolom dari suatu dataframe, gunakan `df[[<nama-kolom-1>, <nama-kolom-2>, <nama-kolom-3>, ...]]`Answer
sales_df[['price_per_unit','quantity']]- Harusnya di data ini ada kolom total harga pembelian yang dinamakan
total_price, tapi sepertinya kolomnya hilang. Tolong buatkan kolomnya berdasarkan data yang ada.
Hint 1
# Perhatikan bahwa total harga pembelian = kuantitas x harga per unitHint 2
# Buat kolom baru dari hasil kali 2 kolom tersebut dengan df[...] = df[...]*df[...].Answer
sales_df['total_price'] = sales_df['price_per_unit']*sales_df['quantity']- Beliau mau tau ada berapa banyak penjualan yang total harganya lebih besar dari $200
Hint
# Untuk memfilter suatu dataset, gunakan df[kondisi]Answer
sales_df[sales_df['total_price'] > 200]- Beliau mau tau ada berapa banyak penjualan yang total harganya berada di kisaran $200-250
Hint
# Gunakan `&` untuk filter dengan 2 kondisi yang dihubungkan operator `dan`.Answer
sales_df[(sales_df['total_price'] > 200) & (sales_df['total_price'] < 200)]- Terakhir, Beliau mau tau ada berapa banyak penjualan yang total harganya di kisaran $200-250 + penjualan 3 barang dalam satu pesanan.
Hint
# Gunakan `|` untuk filter dengan 2 kondisi yang dihubungkan operator `atau`.Answer
condition = (((sales_df['total_price'] > 200) & (sales_df['total_price'] < 200)) | (sales_df['quantity'] == 3))
sales_df[condition]